[Zoom 17-05-2025] Live coding - Lập trình RAG từ đầu
Lập trình RAG từ đầu trên các cơ sở dữ liệu vector khác nhau
1. [Đọc thêm] Thư viện FAISS
1.1. Giới thiệu thư viện Facebook AI Similarity Search (FAISS)
Tìm kiếm vector sử dụng FAISS
Với việc chúng ta có thể embed các văn bản thành vector trong không gian nhiều chiều, việc tìm kiếm các văn bản tương đồng nhau để xây dựng máy tìm kiếm trở nên quan trong hơn bao giờ hết.

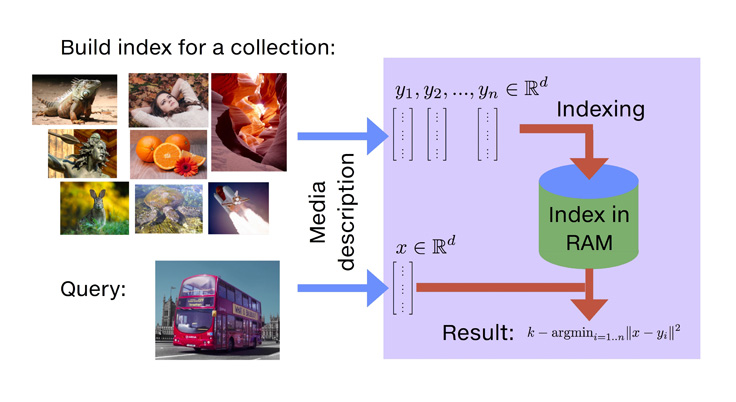
Tuy nhiên việc tìm kiếm này yêu cầu một tốc độ cao nên một trong thư viện đáp ứng tốc độ đó chỉnh là Facebook AI Similarity Search (FAISS).
Ý tưởng chủ đạo của FAISS là tạo ra một loại cấu trúc dữ liệu đặc biệt được gọi là index cho phép tìm embedding tương ứng với embedding đầu vào.
Bạn có thể thêm vector embedding của các câu thông qua hàm sau trong HuggingFace:
embeddings_dataset = comments_dataset.map(
lambda x: {"embeddings": get_embeddings(x["text"]).detach().cpu().numpy()[0]}
)embeddings_dataset.add_faiss_index(column="embeddings")Sau khi bạn đã thêm được vector embedding của các câu vào trong FAISS, bạn có thể thực hành tìm kiếm thông qua hàm sau.
1) Hàm lấy embedding của câu hỏi
question = "How can I load a dataset offline?"
question_embedding = get_embeddings([question]).cpu().detach().numpy()
question_embedding.shape2) Hàm tìm trong embedding dataset embedding nào tương đồng với embedding của câu hỏi
scores, samples = embeddings_dataset.get_nearest_examples(
"embeddings", question_embedding, k=5
)Hàm get_nearest_examples trả về các embedding kèm theo các điểm của từng embedding tương ứng với câu hỏi.
Sau đó bạn có thể sắp xếp các kết quả theo hàm sau:
import pandas as pd
samples_df = pd.DataFrame.from_dict(samples)
samples_df["scores"] = scores
samples_df.sort_values("scores", ascending=False, inplace=True)Các thuật toán đánh chú ý mà FAISS sử dụng:
 Các thuật toán sẽ đánh đổi độ chính xác để lấy thời gian
Các thuật toán sẽ đánh đổi độ chính xác để lấy thời gian
Flat: Thuật toán vét cạn thông thường
Lặp qua từng Vector trong DB/Embeddings
Tính L2 distance giữa query vector và vector hiện tại
Dựa trên tất cả các L2 distance đã tính, tìm ra K vector có khoảng cách ngắn nhắt với query vector
IVF (Inverted File):
Sử dụng Voronoi diagrams, chia nhỏ không than thành nhiều phần nhỏ gọi là Voronoi cells, mỗi cell này có tâm gọi là centroids (tương tự tên gọi trong thuật KNN). Sau đó thuật toán sẽ xác định cell mà query vector nằm bên trong rồi từ đó tính L2 distance giữa query vector và các vector nằm trong đó để tìm ra vector gần vector query nhất.
LHS (Locality Sensitive Hashing)
Nhóm vector vào các buckets và hashing các vector và tối đa việc collisions giữa hai vector, ngược lại với điều chúng ta thường làm như hash password và cố gắng giảm thiểu collisions khi hai password cùng được hash ra một chuỗi.
Việc tối đa collisions chính là cách giúp ta group các vector
HNSW (Hierarchical Navigable Small World Graphs)
HNSW dựa trên ANNS là thuật toán có tốc độ truy vấn thấp nhất.
Small world Graph là đồ thị khi một đỉnh kết nối với các đỉnh mà nó gần nhất.
Ý tưởng các thuật toán sẽ xoay quanh hai cách tối ưu sau:
Giảm chiều vector. Ví dụ dùng thuật toán nén để giảm chiều từ 1024 về 768
Giảm không gian tìm kiếm, phân cụm các vector.
2. Design OOP cho một ứng dụng RAG Chatbot
2.1. Thực hành cách đóng gói OOP cho RAG Chatbot - Trên lớp
Code thực hành trên lớp
https://drive.google.com/file/d/16q8fyToEt5BUtpjsrt3UaJtqsHHklQCq/view?usp=drive_link
3. Video
3.1. [Zoom AI-for-devs-06] 17-05-2025 - Vector Search
So sánh các vector search nổi tiếng
Thực hành lập trình OOP cho dự án RAG