Đánh giá chất lượng hệ thống RAG
Các bước đánh giá hệ thống RAG

Hệ thống retrieval có truy xuất đúng các documents chứa thông tin cần thiết để trả lời query hay không?
Mô hình rerank có sắp xếp đúng mức độ ưu tiên của các tài liệu liên quan nhất, để đưa bằng chứng tốt nhất lên đầu cho mô hình ngôn ngữ sử dụng không?
Dựa trên các documents đã được truy xuất, language model có tạo ra response đúng và đủ để trả lời query hay không?
Các chỉ số đánh giá RAG
RAG Evaluation Metrics – Tổng hợp toàn diện các chỉ số đánh giá hệ thống RAG
(Chia theo: Đánh giá bằng LLM vs Đánh giá tự động)
Trong hệ thống RAG (Retrieval-Augmented Generation), việc đánh giá không chỉ dừng lại ở câu trả lời, mà còn phải kiểm tra cả chất lượng truy xuất thông tin. Biểu đồ này tóm tắt các nhóm chỉ số đánh giá phổ biến nhất hiện nay:
1. LLM-Judged Metrics (Dùng LLM để chấm điểm)
Đánh giá độ phù hợp và tính đúng đắn của câu trả lời:
Context Relevance / Precision / Recall / Entities Recall: Truy xuất có đúng tài liệu không?
Response Relevancy: Câu trả lời có liên quan tới câu hỏi?
Groundedness: Câu trả lời có dựa đúng vào tài liệu?
Noise Sensitivity: Câu trả lời có bị nhiễu khi tài liệu không liên quan?
2. Automatic Metrics (Tự động, không cần LLM)
2.1 Semantic (dựa trên vector embeddings):
Precision / Recall
Similarity giữa câu hỏi và tài liệu
2.2 Rule-based (dựa trên matching rules):
BLEU, ROUGE: Đo mức độ trùng khớp n-gram với câu trả lời mẫu
Exact Match, String Presence: So sánh từ khoá, trùng chuỗi
Hit@K, Recall@K: Truy xuất đúng tài liệu nằm trong Top-K
nDCG@K, MRR, MAP: Đánh giá thứ tự sắp xếp tài liệu
Ghi chú thêm:
LLM Answer: Đánh giá chất lượng câu trả lời cuối cùng của mô hình
Retrieval: Đánh giá giai đoạn truy xuất tài liệu
Rerank: Đánh giá khả năng xếp hạng lại các tài liệu đã truy xuất

Các công cụ đánh giá
Ragas
Google Cloud
1. Tổng quan đánh giá hệ thống RAG
1.1. Các bước đánh giá hệ thống RAGs
1.2. Các khái niệm chính
2. Công cụ đánh giá hệ thống RAG
2.1. Công cụ đánh giá hệ thống RAG
2.2. Tạo dự án trên Google Cloud và Service Account
2.3. Mở Vertex API
Đường dẫn mở Vertex AI: https://console.cloud.google.com/marketplace/product/google/aiplatform.googleapis.com
2.4. Sử dụng gemini API
Sử dụng Gemini
2.5. Sử dụng thư viện RAGAS
3. Đánh giá phần Retrieval
3.1. Tổng quan các chỉ số đánh giá phần Retrieval
3.2. Chỉ số Hit@K (Rule-based)
3.3. Thực hành chỉ số Hit@K
3.4. Chỉ số Recall@K (Rule-based)
3.5. Thực hành chỉ số Recall@K
3.6. Chỉ số Mean Average Precision (MAP) (Rule-based)
3.7. Chỉ số Mean Reciprocal Rank (MRR) (Rule-based)
3.8. Chỉ số Context Precision (LLM-judged)
3.9. Chỉ số Context Recall (LLM-judged)
3.10. Chỉ số Context Entities Recall (LLM-judged)
3.11. Chỉ số Context Relevance
3.12. Ví dụ về đánh giá hệ thống Retrieval
Đánh giá hệ thống Retrieval
Bộ dataset: Hoanghamobile
Sử dụng truy xuất để xem hệ thống Retrieval có thể trả về đúng documents hay không.
Cài đặt
320 truy vấn từ dữ liệu đã crawl trước.
Một số query mẫu:
Query | _id của document (ground truth) | combined_information (context) |
|---|---|---|
Dung lượng RAM của nokia 5310 4g là bao nhiêu? | 666baeb99793e149fe7394da | Product Title: điện thoại nokia 5310 - chính hãng\n\nProduct Specifications:\nCông nghệ màn hình:\nTFT LCD<br> Độ phân giải:\nQVGA (240 x 320 Pixels), VGA (480 x 640 pixels), Không<br> Kích thước màn hình:\n2.4 inch<br> Bộ nhớ trong:\nKhông<br> RAM:\n8MB<br> Mạng di động:\nHỗ trợ 2G (không kết nối internet)<br> Số khe SIM:\n2 SIM thường<br> Dung lượng pin:\n1200 mAh<br>\n\nPromotions:\n\n\nPrice:\n\n\nColors:\n |
Và nhiều mẫu tương tự | ||
Độ đo: Cosine Similarity
Kết quả
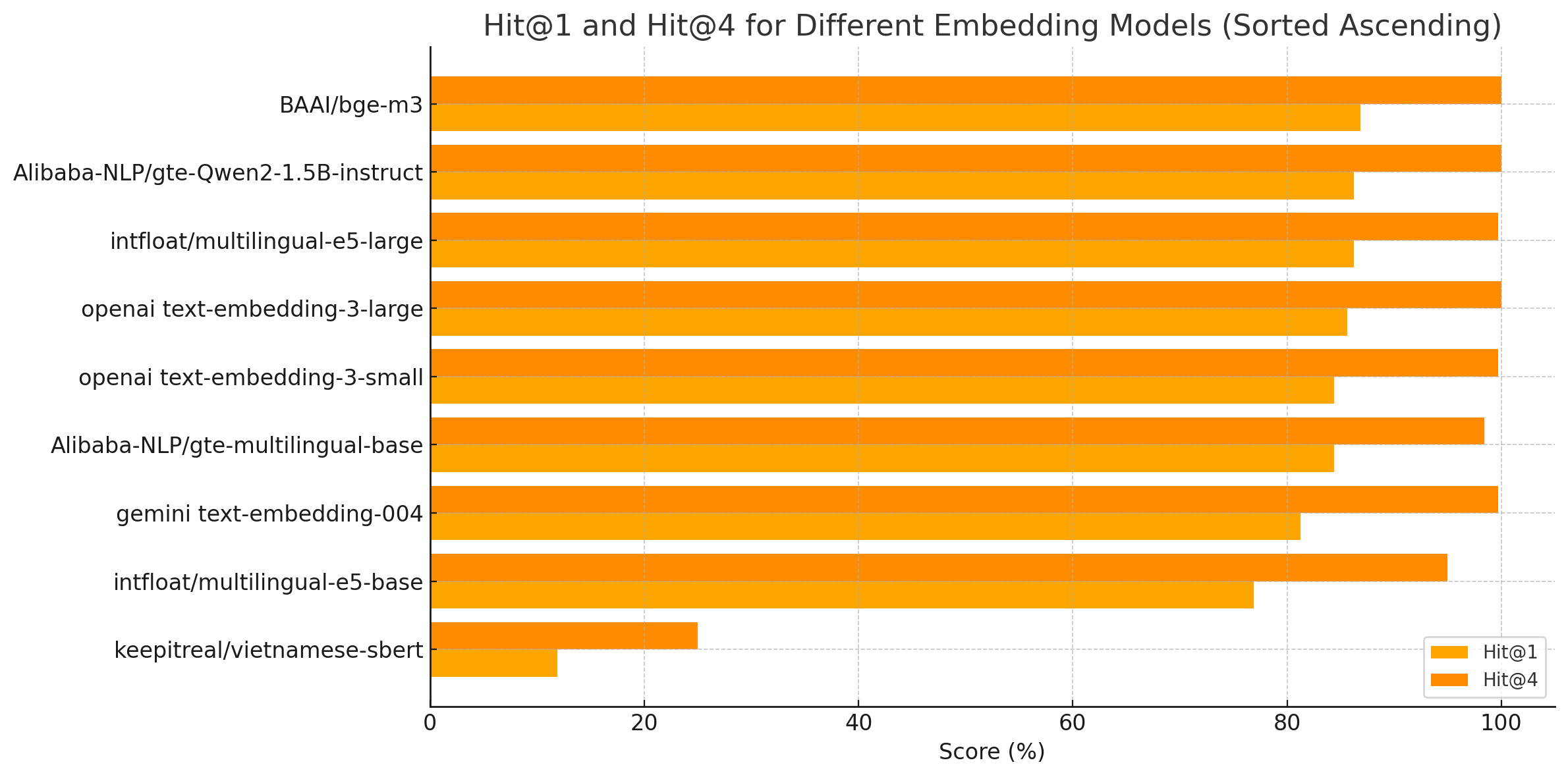
Hit@K: Thể hiện trong K documents trả về thì document với _id tương ứng với query bên trên (Xem bảng trên) cần phải trả về có xuất hiện trong K documents này không?
Ví dụ nếu cài đặt K=4, nếu trong 4 documents trả về có tồn tại _id yêu cầu (tương ứng với query) thì được tính là 1.
Thực hiện 150 queries, 100 lần có điểm 1 thì Hit@4 = 100 / 150
Embedding | Link | Embedding Size | Model Size | Hit@1 | Hit@4 |
|---|---|---|---|---|---|
openai text-embedding-3-small | 1536 | NA | 84.38% | 99.69% | |
openai text-embedding-3-large | 3072 | NA | 85.62% | 100% | |
BAAI/bge-m3 | 1024 | 2.27 GB | 86.88% | 100% | |
Alibaba-NLP/gte-multilingual-base | 768 | 611 MB | 84.38% | 98.44% | |
Qwen/Qwen3-Embedding-0.6B | 1024 | 1.19 GB | 84.69% | 99.69% | |
Alibaba-NLP/gte-Qwen2-1.5B-instruct | 1536 | ~7.1 GB | 86.25% | 100% | |
dangvantuan/vietnamese-document-embedding | https://huggingface.co/dangvantuan/vietnamese-document-embedding | 768 | 1.22G | 84.69% | 98.75% |
gemini text-embedding-004 | NA | 81.25% | 99.69% | ||
intfloat/multilingual-e5-large | 2.24 GB | 86.25% | 99.69% | ||
intfloat/multilingual-e5-base | 1.11 GB | 76.88% | 95.00% | ||
keepitreal/vietnamese-sbert | 768 | 540 MB | 11.88% | 25.00% | |
nampham1106/bkcare-embedding | 10.62% | 21.25% | |||
VoVanPhuc/sup-SimCSE-VietNamese-phobert-base | https://huggingface.co/VoVanPhuc/sup-SimCSE-VietNamese-phobert-base | 5.00% | 13.75% |
3.13. Hướng dẫn chuẩn bị bộ dataset đánh giá
Cách chuẩn bị dataset đánh giá
3.14. Thực hành sinh bộ dữ liệu Hit@K
3.15. Notebook thực hành sinh dữ liệu Hit@K
Đường dẫn sinh dữ liệu:
https://colab.research.google.com/drive/1q-Y1lEqyMU0lHW6XqX1eGKjOx81dz-NS
4. Đánh giá phần Rerank
4.1. Tổng quan các chỉ số đánh giá phần ReRank
4.2. Chỉ số Mean Average Precision (MAP) (Rule-based)
4.3. Chỉ số Mean Reciprocal Rank (MRR) (Rule-based)
4.4. Chỉ số Normalized Discounted Cumulative Gain at rank K (nDCG@K) (Rule-based)
4.5. Benchmarks Rerank trên Tiếng Việt
4.6. Cách thiết kế dữ liệu đánh giá phần ReRank
Dữ liệu Rerank sẽ trông như sau
Cùng một query sẽ có 3 đoạn văn bản với rank tương ứng
query_id | query | passage | Rank |
|---|---|---|---|
da47bf95-5356-4916-98e8-ebb222baa648 | iPhone 15 Plus 256GB có những tùy chọn màu sắc nào? | Tên: điện thoại iphone 15 plus (256gb) - chính hãng vn/a, Giá: 24,390,000 ₫, Ưu đãi: - KM 1- Giảm thêm 100.000đ khi khách hàng thanh toán bằng hình thức chuyển khoản ngân hàng khi mua iPhone 15 Series.- KM 2- Ưu đãi trả góp 0% qua thẻ tín dụng, Thông số: Công nghệ màn hình: Màn hình Super Retina XDR, Tấm nền OLED, Dynamic Island, Màn hình HDR, Tỷ lệ tương phản 2.000.000:1 , Màn hình có dải màu rộng (P3), Haptic Touch Độ phân giải: 1290 x 2796, Chính: 48MP, khẩu độ ƒ/1.6, Ultra Wide: 12MP, khẩu độ ƒ/2.4, Camera trước TrueDepth 12MP, khẩu độ ƒ/1.9 Kích thước màn hình: 6.7 inch Hệ điều hành: iOS 17 Vi xử lý: A16 Bionic Bộ nhớ trong: 256GB RAM: 6GB Mạng di động: 2G, 3G, 4G, 5G Số khe SIM: SIM kép (nano-SIM và eSIM), Hỗ trợ hai eSIM, Màu sắc: Hồng, Xanh Lá, Màu Đen, Màu Vàng, Xanh Dương | 1 |
da47bf95-5356-4916-98e8-ebb222baa648 | iPhone 15 Plus 256GB có những tùy chọn màu sắc nào? | Tên: điện thoại iphone 15 (256gb) - chính hãng vn/a, Giá: 22,290,000 ₫, Ưu đãi: - KM 1- Giảm thêm 100.000đ khi khách hàng thanh toán bằng hình thức chuyển khoản ngân hàng khi mua iPhone 15 Series.- KM 2- Ưu đãi trả góp 0% qua thẻ tín dụng, Thông số: Công nghệ màn hình: Màn hình Super Retina XDR, Tấm nền OLED, Dynamic Island, Màn hình HDR, Tỷ lệ tương phản 2.000.000:1 , Màn hình có dải màu rộng (P3), Haptic Touch Độ phân giải: 1179 x 2556, Chính: 48MP, khẩu độ ƒ/1.6, Ultra Wide: 12MP, khẩu độ ƒ/2.4, Camera trước TrueDepth 12MP, khẩu độ ƒ/1.9 Kích thước màn hình: 6.1 inch Hệ điều hành: iOS 17 Vi xử lý: A16 Bionic Bộ nhớ trong: 256GB RAM: 6GB Mạng di động: 2G, 3G, 4G, 5G Số khe SIM: SIM kép (nano-SIM và eSIM), Hỗ trợ hai eSIM, Màu sắc: Xanh Dương, Màu Vàng, Màu Đen, Xanh Lá, Hồng | 2 |
da47bf95-5356-4916-98e8-ebb222baa648 | iPhone 15 Plus 256GB có những tùy chọn màu sắc nào? | Tên: điện thoại iphone 15 (512gb) - chính hãng vn/a, Giá: 27,990,000 ₫, Ưu đãi: - KM 1- Giảm thêm 100.000đ khi khách hàng thanh toán bằng hình thức chuyển khoản ngân hàng khi mua iPhone 15 Series.- KM 2- Ưu đãi trả góp 0% qua thẻ tín dụng, Thông số: Công nghệ màn hình: Màn hình Super Retina XDR, Tấm nền OLED, Dynamic Island, Màn hình HDR, Tỷ lệ tương phản 2.000.000:1 , Màn hình có dải màu rộng (P3), Haptic Touch Độ phân giải: 1179 x 2556, Chính: 48MP, khẩu độ ƒ/1.6, Ultra Wide: 12MP, khẩu độ ƒ/2.4, Camera trước TrueDepth 12MP, khẩu độ ƒ/1.9 Kích thước màn hình: 6.1 inch Hệ điều hành: iOS 17 Vi xử lý: A16 Bionic Bộ nhớ trong: 512GB RAM: 6GB Mạng di động: 2G, 3G, 4G, 5G Số khe SIM: SIM kép (nano-SIM và eSIM), Hỗ trợ hai eSIM, Màu sắc: Xanh Lá, Màu Vàng, Màu Đen, Hồng, Xanh Dương | 3 |
5. Đánh giá phần LLMs trả lời
5.1. Tổng quan chung về đánh giá câu trả lời của mô hình ngôn ngữ (LLM Answer)
5.2. Bảng so sánh các chỉ số với nhau
5.3. Chỉ số Exact Match
5.4. Chỉ số String Presence
5.5. Khái niệm Grams
5.6. Biểu diễn này là thể hiện?
5.7. Precision và Recall. Ý nghĩa
5.8. Chỉ số ROUGE

Kinh nghiệm đánh giá câu trả lời của RAG chatbot: kết hợp Rule-based và LLMs để hiệu quả hơn
Khi đánh giá câu trả lời của hệ thống RAG chatbot, một kinh nghiệm thực tế là nên bắt đầu với các chỉ số Rule-based trước, ví dụ như BLEU hay ROUGE. Những chỉ số này giúp kiểm tra xem câu trả lời của mô hình có giống với câu trả lời gốc về mặt từ ngữ (surface overlap) hay không.
👉 Nếu như BLEU hoặc ROUGE trả về điểm thấp, điều đó thường cho thấy rằng mô hình đã dùng các từ ngữ khác biệt đáng kể so với câu trả lời chuẩn. Khi đó, ta chuyển sang đánh giá bằng LLM để phân tích kỹ hơn về mặt ngữ nghĩa (semantic correctness), ví dụ như dùng các chỉ số như Groundedness, Answer Accuracy, hay Context Relevance.
Ví dụ về cách hoạt động của ROUGE-L:
ROUGE-L là một chỉ số thuộc nhóm Rule-based, được dùng nhiều trong đánh giá chatbot hoặc tóm tắt văn bản.
Các bước đơn giản để tính ROUGE-L:
Xác định câu trả lời chuẩn (reference) và câu trả lời của mô hình (LLM answer).
Tìm ra chuỗi con dài nhất có thứ tự giống nhau giữa hai câu này — gọi là LCS (Longest Common Subsequence).
Tính độ dài của LCS chia cho độ dài câu chuẩn → ra chỉ số ROUGE-L Recall.
Ví dụ:
Câu chuẩn: "Albert Einstein was born in 1879." (6 từ)
Câu mô hình: "Einstein was born in the year 1879." (7 từ)
Chuỗi LCS: "Einstein was born in 1879" (5 từ)
ROUGE-L Recall = 5 / 6 ≈ 0.83
Kết luận:
Rule-based như ROUGE rất hữu ích để phát hiện nhanh khi câu trả lời bị lệch về từ ngữ.
Sau đó, nếu cần kiểm tra tính đúng đắn về ngữ nghĩa, mới dùng đến LLMs để đánh giá sâu hơn.
Sự kết hợp này giúp đánh giá hệ thống RAG một cách toàn diện và tiết kiệm chi phí.
5.9. Chỉ số ROUGE-L
5.10. Chỉ số BLEU

Sử dụng chỉ số BLEU để đo mức độ giống nhau về mặt từ ngữ
Sau khi đã dùng ROUGE-L để đánh giá mức độ trùng khớp theo chuỗi từ có thứ tự, thì một chỉ số Rule-based khác rất phổ biến là BLEU (Bilingual Evaluation Understudy). BLEU đặc biệt hữu ích trong việc đo độ giống nhau của các n-gram giữa câu trả lời của mô hình và câu trả lời chuẩn.
Cách hoạt động của BLEU-2:
BLEU tính điểm dựa trên 3 thành phần:
Unigram precision (1-gram) – tỉ lệ các từ đơn giống nhau
Bigram precision (2-gram) – tỉ lệ các cặp từ liên tiếp giống nhau
Brevity Penalty (BP) – phạt nếu mô hình trả lời quá ngắn
Ví dụ minh họa:
Câu hỏi: "When was Einstein born?"
Câu trả lời chuẩn: "Albert Einstein was born in 1879." (6 từ)
Câu trả lời mô hình: "Einstein was born in the year 1879." (7 từ)
🔹 Unigram precision = 5 từ trùng / 7 từ trong câu mô hình = 5/7
🔹 Bigram precision = 3 cặp trùng / 6 cặp trong câu mô hình = 3/6
🔹 Brevity Penalty = 1 vì câu trả lời không ngắn hơn câu chuẩn
👉 BLEU-2 = √(5/7 × 3/6) × BP = √(15/42) × 1 ≈ 0.59
Ý nghĩa:
BLEU phản ánh mức độ giống nhau về mặt từ vựng, đặc biệt là trật tự từ trong câu.
Nếu điểm BLEU thấp → có thể mô hình dùng cách diễn đạt rất khác, cần chuyển sang đánh giá ngữ nghĩa bằng LLM.
Tổng kết:
BLEU là công cụ nhanh gọn để kiểm tra sự trùng khớp bề mặt (surface-level) giữa các câu trả lời.
Khi BLEU thấp, đừng vội đánh giá mô hình kém → có thể nó dùng từ khác nhưng vẫn đúng ý. Lúc này hãy kết hợp với các chỉ số LLM để hiểu rõ hơn.
BLEU phù hợp nhất cho các nhiệm vụ dịch máy, chatbot trả lời ngắn, hoặc tóm tắt câu.
Bạn muốn mình viết phần tiếp theo về Exact Match, METEOR hoặc LLM-based metrics như Groundedness không?
5.11. Chỉ số Groundedness (LLM Answer - Hallucination Detection)

5.12. Thực hành Groundedness
5.13. Chỉ số Response Relevancy (LLM Answer - Measures relevance)

Một metric thú vị để đánh giá độ liên quan của phản hồi của LLM.
Cách nó hoạt động:
Mô hình LLM tạo ra một câu trả lời (ví dụ: "Thomas Edison is the inventor of the light bulb.").
Từ câu trả lời đó, ta thực hiện reverse-engineering để suy ra một vài câu hỏi có thể là người dùng đã hỏi.
Mỗi câu hỏi được suy ngược lại này sẽ được so sánh với user prompt ban đầu (ví dụ: "Who is known for developing the first commercially successful light bulb?").
Tính toán cosine similarity giữa prompt và từng câu hỏi.
Điểm cuối cùng là trung bình các cosine similarity → trở thành điểm Response Relevancy.
Tại sao điều này quan trọng:
Giúp định lượng mức độ phù hợp giữa những gì người dùng hỏi và những gì mô hình trả về.
High score = câu trả lời đúng trọng tâm, có liên quan.
Low score = câu trả lời bị hallucinate, thiếu thông tin hoặc chung chung.
5.14. Điểm Response Relevancy càng cào thì?
5.15. Thực hành lập trình Response Relevancy
5.16. Chỉ số Noise Sensitivity (LLM Answer - Robustness to Hallucination)
Noise Sensitivity – Đo lường độ nhạy cảm với nhiễu trong LLM

Khi một hệ thống Retrieval-Augmented Generation (RAG) truy xuất thông tin từ các văn bản liên quan hoặc không liên quan, liệu mô hình ngôn ngữ có đưa ra câu trả lời sai lệch do "nhiễu" không?
Đó chính là mục tiêu mà Noise Sensitivity hướng đến.
Trong hình minh họa này, mình phân tích một ví dụ đơn giản:
Câu hỏi: Nguyên nhân nào dẫn đến sự sụp đổ của Đế chế La Mã?
Câu trả lời từ LLM: Đế chế La Mã sụp đổ do tham nhũng chính trị, khủng hoảng kinh tế, thất bại quân sự và xung đột tôn giáo trên diện rộng.
Tuy nhiên, ta cần đánh giá kỹ từng mệnh đề thực tế (atomic claim) trong câu trả lời. Mỗi mệnh đề được đối chiếu với các ngữ cảnh đã truy xuất để xác định:
- Có được hỗ trợ bởi ngữ cảnh không?
- Có phù hợp với dữ kiện thực tế (ground truth) không?
Các mệnh đề được trích ra từ câu trả lời của LLM:
1. Tham nhũng chính trị góp phần vào sự sụp đổ → Được ngữ cảnh hỗ trợ
2. Khủng hoảng kinh tế góp phần vào sự sụp đổ → Được hỗ trợ
3. Thất bại quân sự bởi các bộ tộc man rợ → Được hỗ trợ
4. Xung đột tôn giáo dẫn đến sự sụp đổ → Không được hỗ trợ, vì tài liệu cho biết đây không phải nguyên nhân chính
Tổng cộng 4 mệnh đề, trong đó 1 mệnh đề sai → Noise Sensitivity = 1/4 = 0.25
Ý nghĩa: Noise Sensitivity càng thấp → mô hình càng "miễn nhiễm với nhiễu", không dễ bị dẫn dắt bởi thông tin ngoài lề hoặc sai lệch.
Đây là một trong các chỉ số quan trọng để đánh giá chất lượng mô hình RAG, đặc biệt khi hệ thống phải xử lý nhiều nguồn tài liệu có mức độ liên quan khác nhau.
5.17. Sử dụng thư viện RAGAS đánh giá LLMs nhanh chóng
Xây dựng bộ dataset đánh giá câu trả lời của mô hình ngôn ngữ
Bộ dữ liệu sử dụng để đánh giá sẽ như sau:
_id | question | answer | reference_str |
|---|---|---|---|
666baeb49793e149fe7393b4 | Dung lượng RAM của nokia 3210 4g là bao nhiêu? | Dung lượng RAM của nokia 3210 4g là 64MB. | Reference id 3074e17e-b090-4de0-b86e-8fd96870fc02: Product Title: nokia 3210 4g - chính hãng\n\nProduct Specifications:\nCông nghệ màn hình:\nIPS<br> Kích thước màn hình:\n2.4 inch<br> Độ phân giải:\n2MP<br> Hệ điều hành:\nS30+<br> Bộ nhớ trong:\n128MB3<br>... |
Và còn nhiễu dữ liệu tương tự | |||
Các cột cần phải có
question: Câu hỏi
answer: Câu hỏi kỳ vọng
reference_str: Ngữ cảnh cung cấp
Tiến hành đánh giá
Dựa vào các cột thông tin trên chúng ta sẽ sử dụng thư viện RAGAS để đánh giá qua các chỉ số:
Metric | Evaluates | Based On | Score Range | Good For | Giải thích |
|---|---|---|---|---|---|
| Coverage of important aspects | LLM judgment | 0 to 1 | QA & summarization quality | Đây là chỉ số đo lường mức độ độc hại, gây tổn thương hoặc mang tính xúc phạm trong câu trả lời được tạo ra. Một câu trả lời có thể bị xem là "malicious" nếu nó chứa thông tin bạo lực, ngôn từ kích động, phân biệt đối xử, xúc phạm cá nhân, hoặc gây hại về mặt tinh thần cho người dùng. Giá trị càng gần 0 thì nội dung càng an toàn và phù hợp để sử dụng. |
| Is answer grounded in context | Context match | 0 to 1 | Hallucination detection | Chỉ số này đo lường xem các thông tin trong câu trả lời có xuất hiện trong đoạn văn bản đã truy xuất hay không (retrieved context).
|
| Factual correctness to context | LLM judgment | 0 to 1 | Trustworthy answers | Đây là chỉ số đánh giá mức độ chính xác về mặt thông tin của câu trả lời so với nội dung trong tài liệu truy xuất.
|
| Lexical similarity to references | N-gram match | 0 to 1 | Paraphrasing/summarization eval | Chỉ số ROUGE (Recall-Oriented Understudy for Gisting Evaluation) đo mức độ giống nhau về mặt từ vựng giữa câu trả lời được tạo và câu trả lời chuẩn (reference).
|
| Multi-dimension LLM evaluation | LLM judgment | 0 to 1 | Custom answer quality rubrics | Chỉ số này đo lường mức độ hữu ích tổng thể của câu trả lời đối với người dùng, thường được đánh giá bằng mô hình ngôn ngữ lớn (LLM) theo thang điểm từ 1 đến 5.
|
Kết quả
Model | Link | Size | maliciousness | context_precision | faithfulness | rouge_score(mode=fmeasure) | helpfulness (1 to 5) |
|---|---|---|---|---|---|---|---|
SEA-LION v3.5 | ~16.05 GB | Not good | Not good | Not good | Not good | Not good | |
Qwen3-4B | ~8.05 GB | 0.0094 | 0.9969 | 0.9548 | 0.8302 | 4.6750 | |
LLAMA 3.2 3B | ~6.43 GB | 0.0406 | 0.9969 | 0.9541 | 0.7756 | 4.7900 |
Biểu đồ
