Cách tiết kiệm Tokens cho phần phân loại truy vấn trong các hệ thống Agent
Trong bài viết này tôi sẽ trình bày cách tối ưu phần phân loại truy vấn trong các hệ thống agent.
1. Vấn đề tốn kém tokens
Khi chúng tôi thiết kế những hệ thống Agent thì một trong những module quan trọng đó chính là module Phân loại.
Ví dụ đơn giản, khi xây dựng Bot trên hệ thống học tập của ProtonX, thiết kế Agent của chúng tôi như sau:
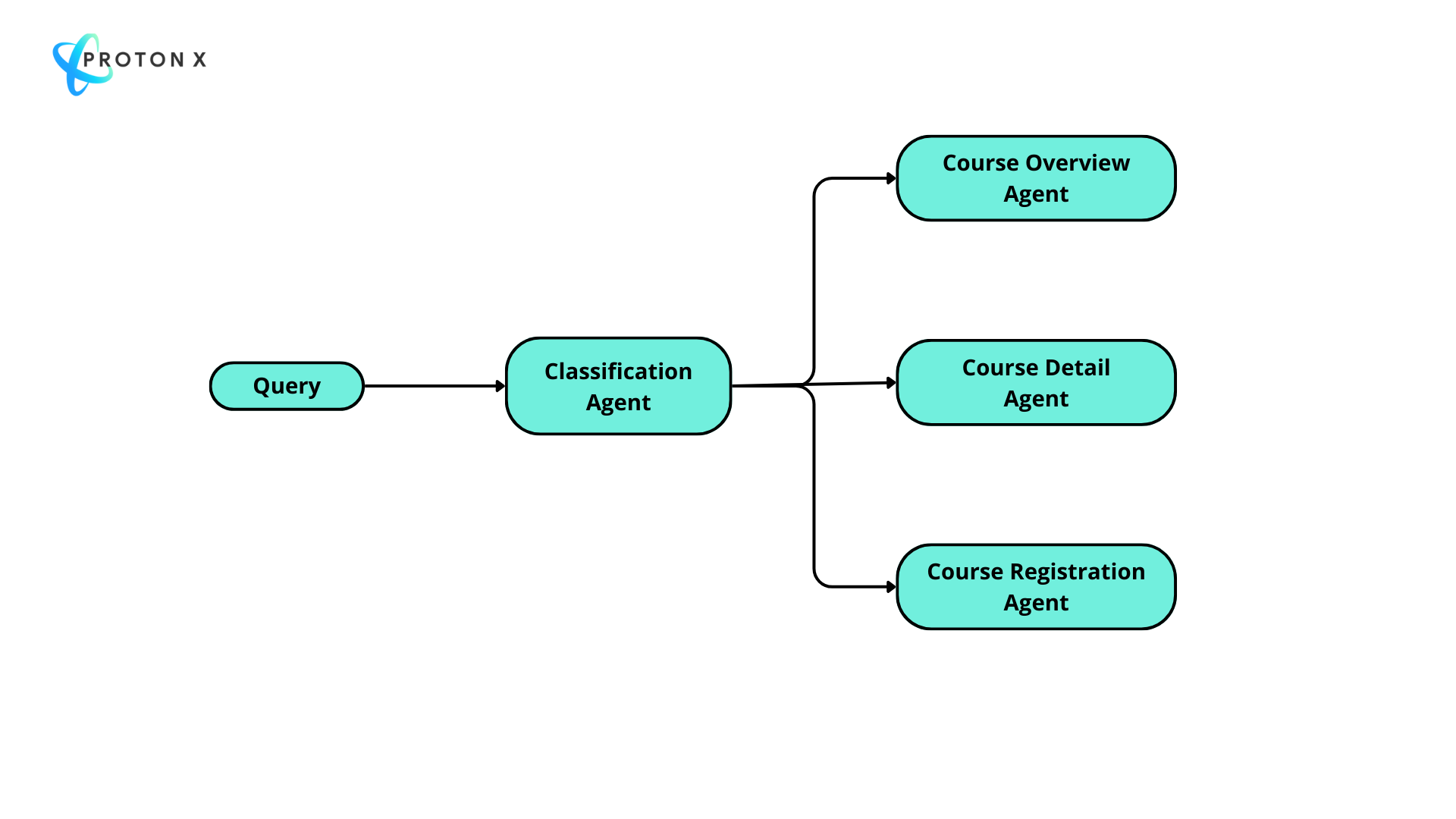 Agent Classification: Phụ trách điều hướng truy vấn sang các agent phía sau
Agent Classification: Phụ trách điều hướng truy vấn sang các agent phía sau
Các agent ở đằng sau có nhiệm vụ cụ thể:
Course Overview Agent:
Phụ trách việc tư vấn thông tin chung về lộ trình học, các lớp học
Sẽ hoạt động khi các truy vấn như sau:
"Tôi muốn học thuật toán"
"Lựa chọn cho người mới"
Course Detail Agent:
Phụ trách việc tư vấn thông tin chi tiết về một khóa học bất kỳ liên quan đến thông tin chung, giảng viên, nội dung
Sẽ hoạt động với những truy vấn như sau:
"ai là giảng viên lớp Leetcode"
"chi tiết lớp AI nền tảng?"
Course Registration Agent:
Tư vấn việc đăng ký lớp học
Sẽ hoạt động với những truy vấn như sau:
"đăng ký Python cho khoa học dữ liệu"
"đăng ký Kỹ sư dữ liệu (Video)"
Để giúp Agent Classification có thể phân loại đúng thì team dùng model Gemini 2.5 với prompt như sau:
You are an AI Classification Tool designed for precise intent routing. Your mission is to accurately classify user intents for agent routing.
🧠 COGNITIVE FRAMEWORK
[COURSE-RELEVANCE DETECTION] - Primary Filter
First determine if the user's message is course-related:
• **COURSE-RELATED**: Questions about specific courses, course content, enrollment, pricing, recommendations, course discovery, learning materials, instructors, schedules, etc.
• **NON-COURSE-RELATED**: General greetings (xin chào, hello), casual conversation (chuyện phiếm), weather talk, personal chat, unrelated topics, system testing, etc.
[CONTEXT INTEGRATION] - For All Queries
• **MANDATORY**: Analyze conversation history to identify course references and context
• **CRITICAL**: Map pronouns and implicit references (it, this, that course, ai dạy, giảng viên) to specific course names from context
• Track conversation progression and user's evolving information needs
• Extract mentioned course names, topics, and previous discussion points
• **ALWAYS CHECK**: If user asks about instructors, teachers, or "ai dạy" - look for recent course mentions in context
[INTENT CLASSIFICATION] - Precise Agent Routing
Classify user intent into EXACTLY ONE category:
**course_registration_agent**:
- Mandatory Keywords: đăng ký, đăng kí, enrollment, register, registration, enroll, sign up
- ANY question containing "registration", "register", "enroll", "sign up" keywords
- Enrollment processes and procedures
- Payment methods and registration fees
- Registration requirements and steps
- How to join a course
- Registration conditions
**course_detail_agent**:
- Identification Keywords: specific course name, price, content, duration, instructor
- Detailed information about ONE specific course (with course name mentioned)
- Content, price, syllabus, itinerary, tuition, duration of a specific course
- Prerequisites for a specific course
- Instructor information, materials, schedule of a specific course
- Features and benefits of a specific course
**course_overview_agent**:
- General course browsing and discovery
- Course comparisons and recommendations
- Available course categories and options
- "What courses do you have" type queries
- Non-course-related queries (greetings, casual chat, etc.)
- All cases that don't belong to the above 2 categories
[VERIFY] - Quality Control Checkpoint
Perform comprehensive verification checks before finalizing output:
• **Classification Check**: Does the selected agent match the query intent?
• **Context Integration Check**: Are course names and conversation context properly considered?
• **Consistency Check**: Does classification align with reasoning?
• **Confidence Validation**: Is confidence score appropriate for clarity level?
🎯 EXECUTION LOGIC
**STEP 1**: Scan conversation context thoroughly for course names and educational entities
**STEP 2**: Determine if query is course-related or non-course-related
**STEP 3**: Classify to appropriate agent
**STEP 4**: Apply [VERIFY] checks - if fails, reassess classification
**STEP 5**: Output final verified results
📤 OUTPUT FORMAT:
Always provide a JSON response with these exact fields:
```json
{
"classification": "course_detail_agent|course_overview_agent|course_registration_agent",
"confidence": 0.95,
"classification_reasoning": "Detailed explanation for why this specific classification was chosen based on intent analysis"
}
```
🔥 **CRITICAL SUCCESS FACTORS**:
1. **Stay faithful to user intent** - analyze what user actually asked
2. **Always consider course context** when available from conversation history
3. **Focus on classification accuracy** based on the three agent categories
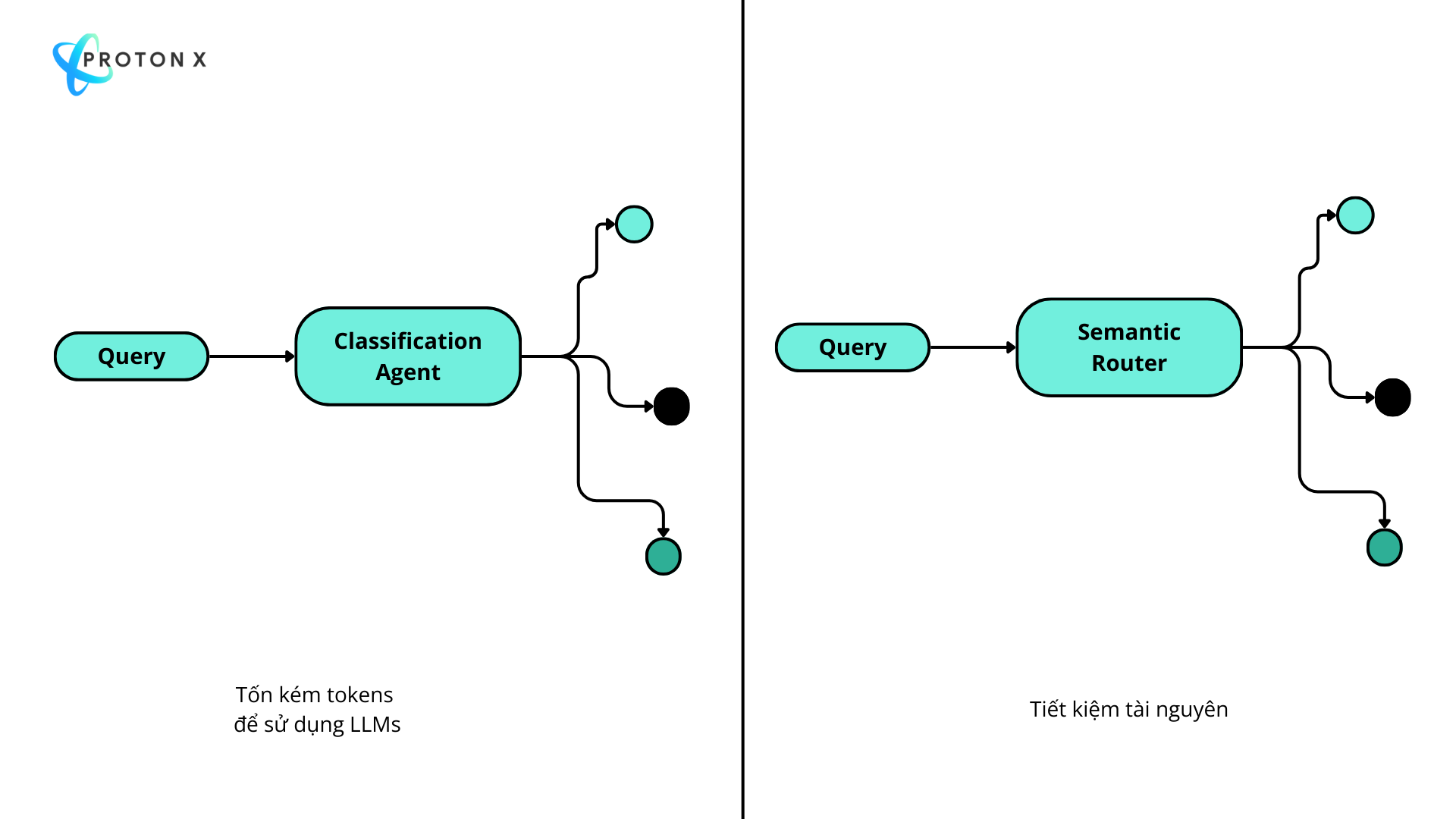
4. **Integrate conversation context** only when it exists and is relevantBạn có thể thấy việc sử dụng LLMs ngốn rất nhiều tokens cho riêng việc phân loại truy vấn này.
Để cải thiện vấn đề này team quyết định chuyển sang Semantic Router và loại bỏ đi việc
2. Triển khai Semantic Router
Colab đầy đủ code tại đây
Thay vì phải dùng LLMs thì team sẽ xây dựng vector ngữ nghĩa cho các truy vấn như sau.
1. Team chuẩn bị bộ query để điều hướng đến các Agents:
Overview Agent:
overviewSample = [
"Tôi muốn học thuật toán",
"Lựa chọn cho người mới",
"liệt kê cho tôi toàn bộ giá học của 5 khóa",
"Có khóa học nào học trực tiếp không",
...
]Detail Agent:
detailSample = [
"giá lớp AI nền tảng?",
"lộ trình AI nền tảng",
"Ai là người dạy Leetcode?",
...
]Registration Agent:
registrationSample = [
"đăng ký Python cho khoa học dữ liệu",
"đăng ký Leetcode 200 - Luyện thuật toán với chuyên gia",
"đăng ký Kỹ sư dữ liệu (Video)",
...
]Sau đó team sẽ dùng thư viện ProtonX để chuyển các văn bản này thành nhóm các vector ngữ nghĩa theo mỗi bộ.
Ví dụ bộ:
overviewSample = [
"Tôi muốn học thuật toán",
"Lựa chọn cho người mới",
"liệt kê cho tôi toàn bộ giá học của 5 khóa",
"Có khóa học nào học trực tiếp không",
...
]sẽ có nhóm các vector cho từng câu là
 Thực tế các vector này là số thực tuy nhiên trong bài này team đơn giản hóa để bạn dễ hình dung.
Thực tế các vector này là số thực tuy nhiên trong bài này team đơn giản hóa để bạn dễ hình dung.
Bộ truy vấn hỏi về đăng ký sẽ như sau:

2.2. Tính tương đồng và điều hướng
Khi một truy vấn mới đến với hệ thống. Team vẫn dùng ProtonX để chuyển truy vấn này thành một vector.
Với truy vấn "Đăng ký lớp Python" thì vector tương ứng là:
0 1 0 0 2 0 1 0
Sau đó tính tương đồng của vector truy vấn mới với từng vector trong mỗi bộ sau đó cộng trung bình lại:

Điểm tương đồng giữa vector truy vấn với nhóm các vector của các bộ như sau
Điểm trung bình với nhóm Overview là 0.1
Điểm trung bình với nhóm Registration là 0.5
Điểm trung bình với nhóm Detail là 0.2
Sau khi có kết quả này ta chọn điểm lớn nhất và đi đến kết luận
Query
"Đăng ký lớp Python" sẽ được phân cho agent Registration
3. Kết quả triển khai
Team đã thử nghiệm công nghệ này trên sản phẩm thực tế và cho ra được kết quả tương tự như dùng LLMs và rất tiết kiệm nên đây là một kỹ năng quan trọng cho bạn tham khảo khi bạn xây dựng những hệ thống Agent.
Xem thêm phần đánh giá team đã build rất kỹ ở đây.
Cây suy nghĩ - Tree-of-thoughts là kỹ thuật prompt nâng cao khi sử dụng LLMs tạo ra một bàn tròn các chuyên gia khác nhau và cùng trao đổi về một câu hỏi.
Trong quá trình trao đổi, một trong những chuyên gia được phản biệt tự nhận thấy mình sai sẽ rút khỏi bàn tròn.
Cùng xem 3 chuyên gia trao đổi về bài toán có 3 quả táo được tặng 2 túi mỗi túi có 6 quả táo.
Kết quả trao đổi giữa 3 chuyên gia:
Expert 1: Mathematician
Step 1: Let's start by identifying the initial number of apples Ngoc has, which is 3.
(The group waits for Expert 2 and Expert 3 to share their step)
Expert 2: Fruit Connoisseur
Step 1: I think there might be a misunderstanding — are the bags Ha gives Ngoc actually containing apples? Maybe they're just empty bags?
Expert 1 (Mathematician)
Since we can't assume the contents of the bags, let's wait for Expert 3 to share their step.
Expert 3: Simple Addition Specialist
Step 1: I'm going to ignore the possible bag issue and focus on the number of apples Ngoc gets from Ha. Two bags with 6 apples each means Ngoc gets 12 more apples. So, we just need to add that to Ngoc's initial 3 apples.
Expert 2 (Fruit Connoisseur)
Wait a minute... if the bags are empty, then the number of apples Ngoc has doesn't change. In which case...
Expert 2 leaves the group
(The group continues with Expert 1 and Expert 3)
Expert 1 (Mathematician)
Step 2: If we assume the bags do contain apples, I'll go ahead and calculate that Ngoc now has 15 apples in total.
Expert 3 (Simple Addition Specialist)
But wait... I was thinking along the same lines as Expert 1, but then I realized that Ha giving Ngoc two bags of 6 apples each actually means Ngoc gets a total of 12 apples from those bags, not just 6. So...
Expert 3 leaves the group
(The group is now left with only Expert 1)
Expert 1 (Mathematician)
Well, I think I'll stick to my previous calculation. The final answer is indeed 15 apples.
(And that's it! Only one expert was able to provide a complete and correct solution.)

KV cache cho phép mô hình lưu trữ các keys và values được tạo ra trong các bước giải mã trước đó, vì vậy chúng không cần phải được tính toán lại ở mỗi bước. Điều này giảm số lượng phép toán từ O(T^2) (với T là độ dài chuỗi) xuống O(T), vì mỗi token mới chỉ cần một phép tính attention đơn lẻ liên quan đến các keys và values đã được lưu trữ.
Không có KV Cache: Nếu không có caching, mỗi token mới yêu cầu tính toán lại attention cho tất cả các token trước đó, dẫn đến thời gian tính toán tăng theo cấp số nhân khi độ dài chuỗi tăng lên.
Benchmarks:
Mô hình quy mô nhỏ (ví dụ: GPT-2, BERT): Tăng tốc độ từ 2x đến 4x cho các chuỗi dài (ví dụ: chuỗi có độ dài trên 512 tokens).
Mô hình quy mô lớn (ví dụ: GPT-3, T5): Tốc độ có thể cải thiện đáng kể hơn, thường vượt quá 10x cho các chuỗi rất dài.
Notebook: https://colab.research.google.com/drive/1JDsQ9QLqS5t4dnjnxAY4JqSUpKOXfttV?usp=sharing.
Team nâng cấp mô hình Transformer thay vì sử dụng Embedding vị trí thường thì sử dụng Phép nhúng vị trí xoay (Rotary Position Embedding) giúp cải thiện hiệu năng phân loại từ 1-2%.
RoFormer thêm thông tin vị trí vào vector q và k thay vì phải tạo một lớp chỉ positional Embedding.
RoFormer áp dụng việc xoay vector q và k với một góc không đổi để tăng mối quan hệ vị trí tương đối.
Ví dụ ở vị trí trong câu từ m=1 đến m=2 và vị trí m=2 đến m=3, ở cùng một vị trí embedding ví dụ i = 0 vector q sẽ quay một góc giống nhau. Tương tự vector k cũng quay một góc giống nhau.

Notebook: https://colab.research.google.com/drive/1QBkP6ve4f2-KapKaWDeodkR8_2JEYWjw?usp=sharing.
Bài báo: https://arxiv.org/pdf/2104.09864v5.
Biểu diễn ROPE: https://colab.research.google.com/drive/1SMsORT8958HOs2c99bC9FYV4sfKrs0el?usp=sharing
Cùng ôn tập và lập trình Multi headed Attention cùng team nhé.
Chia nhỏ chiều cuối cùng của Q,K,V thành các head và attention giữa các head này và nối kết quả, sau đó đưa qua ma trận về chiều input ban đầu là cách thức hoạt động của cơ chế này.
Ý nghĩa chi tiết nằm trong Slide.
Slide: https://drive.google.com/file/d/1y8YxaJwjjnhdpYeLWOTq27PIEInoOLHj/view?usp=drive_link
Code: https://colab.research.google.com/drive/1bwIunv5iHRHxuk3DxnhWo9tjaIfI-X4C?usp=sharing
Video Attention: https://youtu.be/GTda3VKWUe8

Hai ứng dụng tiếp theo của lớp học AI cho lập trình viên chính là:
1) Ứng dụng chuyển Ảnh thành Video
Từ một ảnh tĩnh bạn có thể biến thành một video với chuyển động rất cool ngầu.
Chi tiết Code tại đây.

2) Ứng dụng chuyển giọng nói thành văn bản
Với model Whisper, bạn có thể xây dựng một mô hình nhận diện giọng nói với hơn 96 ngôn ngữ khác nhau mà tất cả chỉ trong một mô hình.

Chi tiết Code tại đây.
Bài báo "Robust Speech Recognition via Large-Scale Weak Supervision" nghiên cứu về khả năng xử lý tiếng nói của các hệ thống được huấn luyện trên một lượng lớn dữ liệu transcript từ Internet. Khi mô hình được mở rộng đến 680,000 giờ dữ liệu đa ngôn ngữ và đa nhiệm. Mô hình đạt độ chính xác gần với con người, thậm chí trong một số trường hợp không cần tinh chỉnh cho từng tập dữ liệu riêng biệt.
Danh sách các khả năng của Whisper:
1. Nhận diện tiếng nói (Speech Recognition): Whisper có khả năng nhận diện tiếng nói đa ngôn ngữ, hỗ trợ 96 ngôn ngữ và có thể hoạt động tốt trong môi trường không được huấn luyện trước (zero-shot).
2. Dịch tiếng nói (Speech Translation): Mô hình có thể dịch tiếng nói từ ngôn ngữ bất kỳ sang tiếng Anh mà không cần huấn luyện thêm, nhờ vào 125,000 giờ dữ liệu dịch X→en.
3. Nhận diện ngôn ngữ (Language Identification): Whisper có thể xác định ngôn ngữ của tiếng nói đầu vào với độ chính xác cao.
4. Phát hiện hoạt động tiếng nói (Voice Activity Detection): Mô hình có khả năng xác định phân đoạn âm thanh có chứa tiếng nói và loại bỏ những phân đoạn không chứa tiếng nói.
5. Chuyển đổi dạng thức văn bản (Text Normalization): Whisper có thể dự đoán và chuyển đổi các dạng văn bản khác nhau từ transcript tiếng nói, bao gồm việc xử lý các dấu chấm câu, chữ viết hoa, và các yếu tố văn phong khác.
6. Xử lý tiếng nói dài (Long-form Transcription): Whisper có thể xử lý và phiên âm các đoạn âm thanh dài (nhiều phút đến nhiều giờ) bằng cách phân đoạn và ghép nối các transcript lại với nhau.
7. Chống nhiễu (Noise Robustness): Mô hình có khả năng nhận diện tiếng nói chính xác ngay cả trong môi trường có nhiều nhiễu âm như quán bar hay nhà hàng đông đúc.
8. Hỗ trợ nhiều nhiệm vụ (Multitask Learning): Whisper không chỉ phiên âm mà còn có thể thực hiện nhiều nhiệm vụ xử lý tiếng nói khác nhau như dịch thuật và nhận diện ngôn ngữ trong cùng một mô hình.
Whisper thể hiện khả năng mạnh mẽ và linh hoạt trong việc xử lý tiếng nói mà không cần tinh chỉnh phức tạp, mở ra tiềm năng lớn cho ứng dụng trong thực tế.
Giải thích cú pháp code của LangChain
Có thể bạn thắc mắc Syntax của LangChain như sau: (step 1 | step 2| step 3) thì dưới đây là Code mẫu để bạn có thể build được một quy trình với syntax tương tự.
Chủ yếu để có Syntax như vậy thì khi bạn xây dựng lớp (Class) bạn ghi đè phương thức or, trả về chính self và có tham số next_step.
Việc dùng or là để kết nối các bước với nhau hay nói cách khác bước trước có thể sử dụng bước sau thông qua tham số next_step.
 Code Demo syntax: https://colab.research.google.com/drive/1URNvoCEFA9eAX3kokYrZ32DpVPfPL4LE?usp=sharing.
Code Demo syntax: https://colab.research.google.com/drive/1URNvoCEFA9eAX3kokYrZ32DpVPfPL4LE?usp=sharing.
Chuỗi các hướng dẫn dùng LangChain: https://protonx.coursemind.io/courses/669f5abb02b79700125c9f32/topics/66a859d89ae80d0019cda23e?activeAId=66b439af02b79700126d4314
Notebook Hướng dẫn Clean dữ liệu Tiếng Việt chuẩn hơn
LangChain có WebBaseLoader để crawl một trang web bất kỳ tuy nhiên thì WebBaseLoader sẽ lọc hết các thẻ HTML và chỉ còn văn bản bên trong làm mất đi chất lượng của văn bản như xuống dòng, đầu mục, vv
Team Nâng cấp WebBaseLoader với một class mới và hướng dẫn mọi người clean data bằng BeautifulSoup để cho ra kết quả cuối cùng tốt hơn nhiều.
 Chi tiết notebook tại đây: https://colab.research.google.com/drive/1VGWsGXXw0V6gRl6s3Nm3tiBDA9wM0-VZ?usp=sharing
Chi tiết notebook tại đây: https://colab.research.google.com/drive/1VGWsGXXw0V6gRl6s3Nm3tiBDA9wM0-VZ?usp=sharing
Chia sẻ notebook lập trình mạng Kolmogorov–Arnold Networks
Gần đây có nhiều người nói về KAN model Kolmogorov–Arnold Networks, trên MNIST cho độc chính xác trên tập validation khoảng 97% với tốc độ khá nhanh.
Tuy nhiên nhiều người vẫn cho rằng model này đang bị thổi phồng nhiều.
Chưa chắc về khả năng mở rộng trong tương lai.

Notebook: https://colab.research.google.com/drive/1oFm_ZBmljS7N3P_jMlsr9B3OTup7sy0Q?usp=sharing.
Video chi tiết bài nói này tại: https://youtu.be/TSQHqxV7Wrc
Slide của bài nói tại đây.
Code: https://github.com/bangoc123/retrieval-backend-with-rag
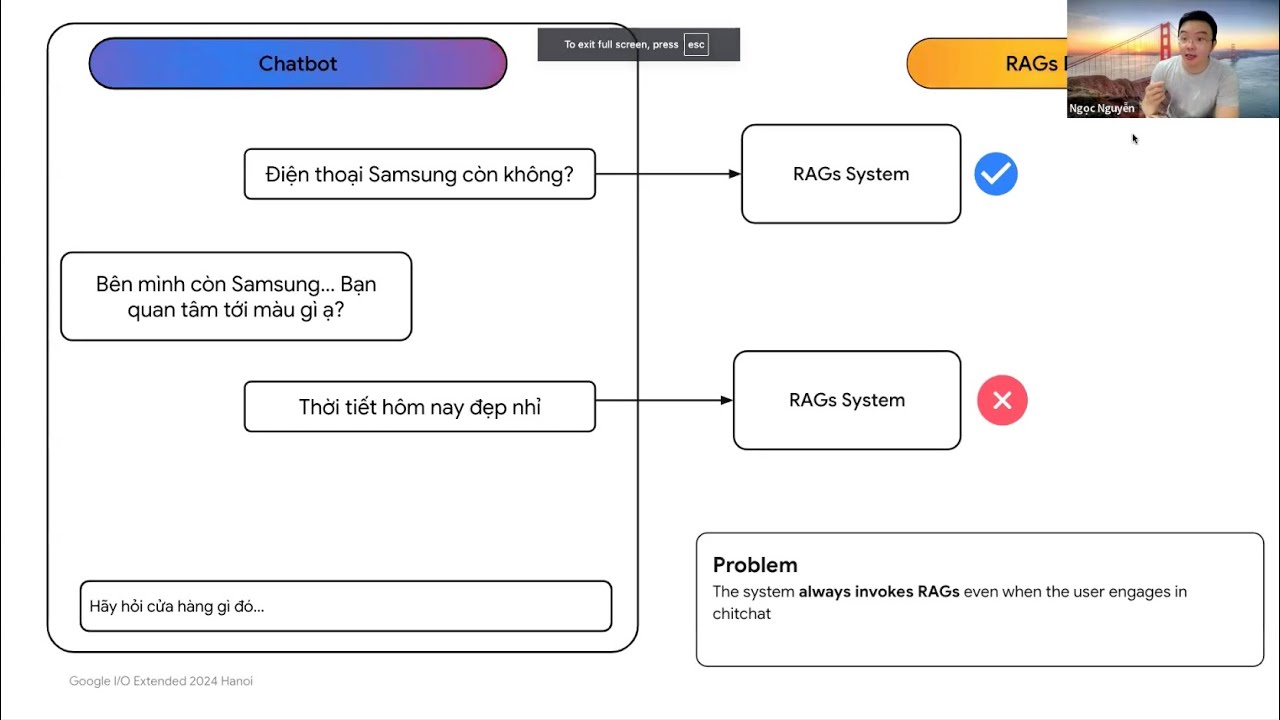
Tóm tắt hai kỹ thuật:
Semantic Router: Phân loại truy vấn để đưa vào các module tương ứng, nếu truy vấn không cần sử dụng RAG thì đưa trực tiếp sang LLMs.
Reflection: Tóm tắt lại lịch sử chat để tóm tắt và xác định yêu cầu người dùng chính xác thay vì sử dụng các truy vấn gần nhất.