Lời giải chi tiết cuộc thi ChatGPT ngày 01/04/2023.
Thực hành lại cuộc thi này trước khi xem lời giải.
Đề bài gồm 14 câu trải dài trên việc hiểu 4 mô hình:
Câu 1
Với những task NLP hiện tại thì cách làm hiệu quả đó là
- Bạn xây dựng một pre-trained model trên dữ liệu không có nhãn, có thể là ngôn ngữ, âm thanh. Dữ liệu này chỉ bao gồm những đoạn văn bản/âm thanh không nhãn. Bạn train model này thông qua nhiều cách khác nhau, ví dụ:
- Bert thì sử dụng các từ xung quanh để dự đoán từ bị thiếu
- GPT thì sử dụng các từ phía trước để dự đoán từ tiếp theo
Sau khi đã có model chúng ta gọi là Pre-trained model và bạn sẽ sử dụng model này để fine tune trên các task khác nhau với những bộ dữ liệu có nhãn.
Cho nên trong trường hợp này đáp án số 4 Generative pre-training trên một tập da đạng văn bản không gán nhãn, sau đó sử dụng mô hình này để fine-tuning trên các task cụ thể. là chính xác.
Câu 2
Ngay ở phần Abstract của bài báo: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf kỹ thuật train GPT đã được đề cập

GPT sẽ được đào tạo trên một lượng lớn văn bản không có nhãn, sau đó trên những task NLP cụ thể, ta sẽ sử dụng pre-trained model này để finetune trên dữ liệu có nhãn.
Câu 3

GPT-1 Unsupervised Pre-trained được đào tạo trên bộ dữ liệu BooksCorpus
Câu 4
BPE là thuật toán tách đơn vị ngôn ngữ khá phổ biến trong các mô hình hiện đại, điểm lợi khi sử dụng thuật toán này đó là giải quyết được vấn đề khi gặp những từ không nằm trong bộ từ điển mà ta hay gọi là token <UNK> hoặc <OOV>. Xem thêm về tách từ tại đây.
Chi tiết hơn về cách hoạt động của BPE bạn có thể xem trong link này
Câu 5
Bộ dữ liệu LAMBADA dùng để kiểm tra khả năng mô hình có thể học được mối quan hệ giữa các thành phần cách xa nhau trong câu hay không.

Mô hình yêu cầu phải dự đoán đúng ra từ cuối trong một câu dài, để làm được điều này mô hình cần nắm bắt được các thông tin có tính ảnh hưởng từ đầu đến cuối câu.
Câu 6
Sau khi đã có pre-trained model của GPT2, ta có thể sử dụng để fine-tune trên bài toán rút gọn văn bản (Summarization):

GPT-2 sử dụng token TL;DR để xác định việc decoding ra văn bản rút gọn là hoàn tất cũng giống các bài toán khác sử dụng token <end>.
Câu 7
Từ GPT-3 chúng ta làm quen những khái niệm rất mới và trở nên rất thành công của ChatGPT.
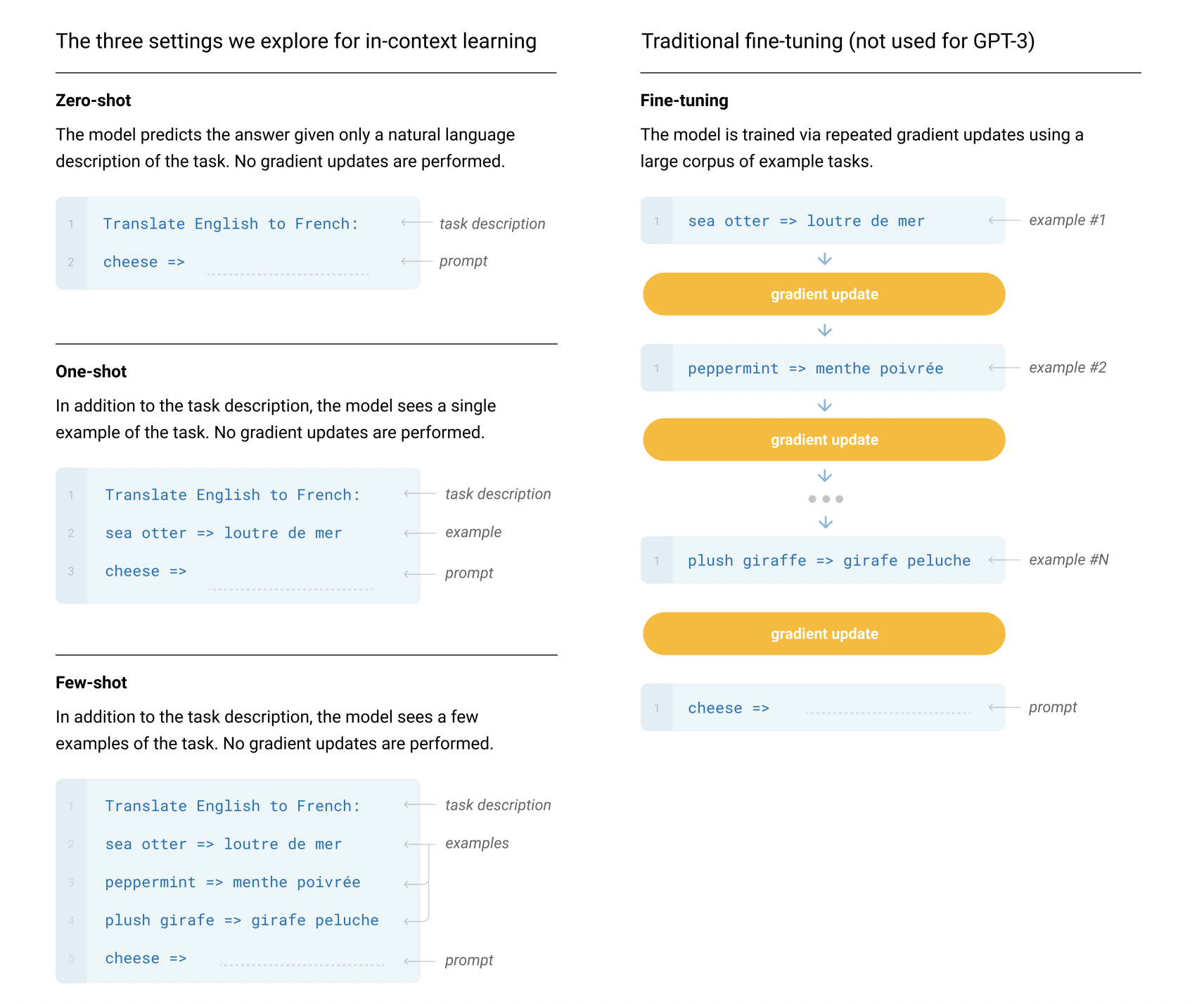
Các khái niệm in-context learning tức là với một task NLP cụ thể ta không cần phải fine-tune lại mô hình theo dữ liệu có nhãn của task đó mà trong quá trình inference, ta có hoặc không cung cấp các mẫu để mô hình hiểu được mục tiêu của task này.
Ví dụ đơn giản, bạn đã train xong một mô hình ngôn ngữ GPT-3. Thay vì bạn fine tune mô hình này trên một bài toán dịch máy với các mẫu là câu đầu vào-câu đầu ra thì bạn tiến hành như sau:
- Zero-shot:
- Bạn nhập yêu cầu mô hình tiến hành dịch và cung cấp luôn câu đầu vào muốn dịch
- One-shot:
- Bạn nhập yêu cầu mô hình tiến hành dịch và cung cấp một mẫu (one-shot) sau đó cung cấp câu đầu vào muốn dịch
- Few-shot
- Bạn nhập yêu cầu mô hình tiến hành dịch và cung cấp một vài mẫu (few-shot) sau đó cung cấp câu đầu vào muốn dịch
Chi tiết ở ảnh phía dưới. Điều đáng chú ý là mô hình dựa trên yêu cầu và một vài mẫu là có thể cho ra kết quả tốt, tất nhiên vẫn chưa thể bằng các kết quả SOTA của việc fine-tune nhưng đây là cách rất tốt để scale mô hình. Toàn bộ quá trình này không yêu cầu training - hay như bài báo dùng cụm từ gradient updates.
Câu 8
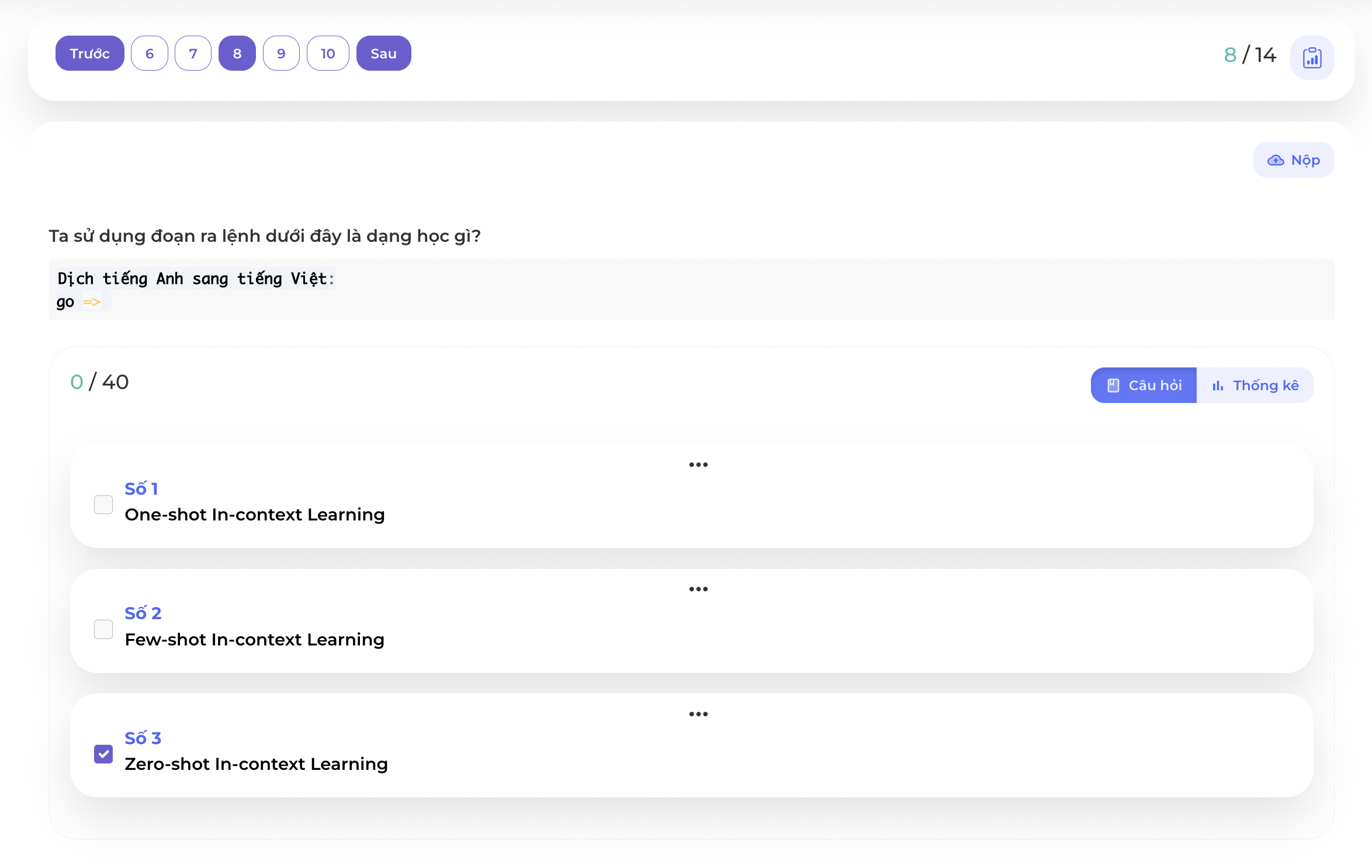
Như miêu tả bên trên thì đây chính là một điển hình của Zero-shot In-context Learning khi mà ta không cung cấp mẫu cho mô hình mà chỉ đưa hướng dẫn.
Câu 9
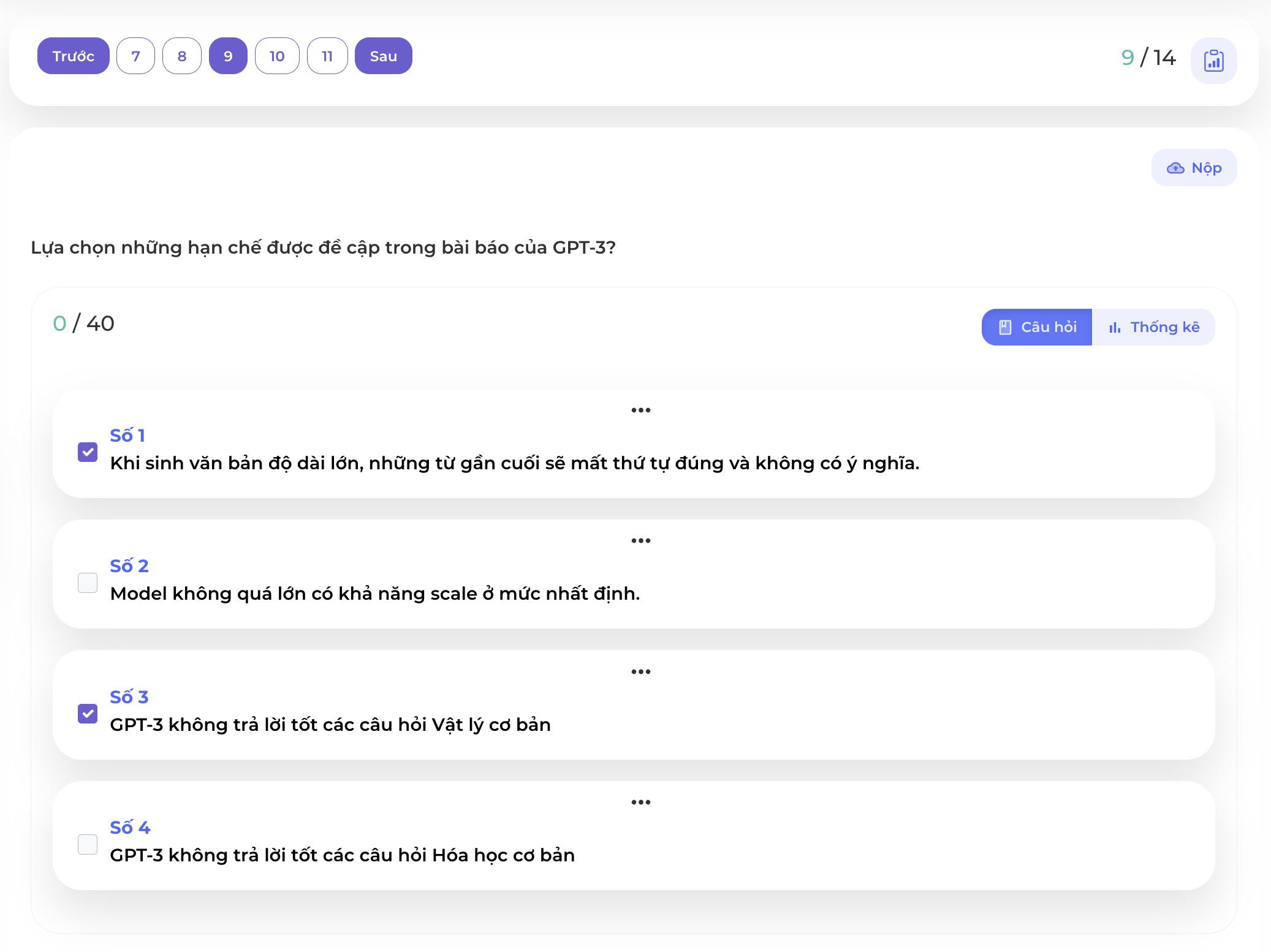
Trong bài báo về GPT-3 mục 5 có nhắc đến các hạn chế của model này:

Điểm yếu đầu tiên là ta thấy đó là khi sinh văn bản dài, các từ sinh ra bắt đầu trở nên vô nghĩa không liên quan đến ngữ cảnh hoặc bạn sẽ gặp trường hợp các từ/cụm từ sinh ra lặp đi lặp lại.
Ngoài ra ở thời điểm này, mô hình vẫn còn yếu trên các task yêu cầu suy luận cao như liên quan tới chủ đề Vật lý:

Chủ đề Hóa học không được nhắc trong bài báo này. Ngoài ra mô hình GPT-3 có kích cỡ rất lớn, rất khó để scale trên diện rộng.
Câu 10
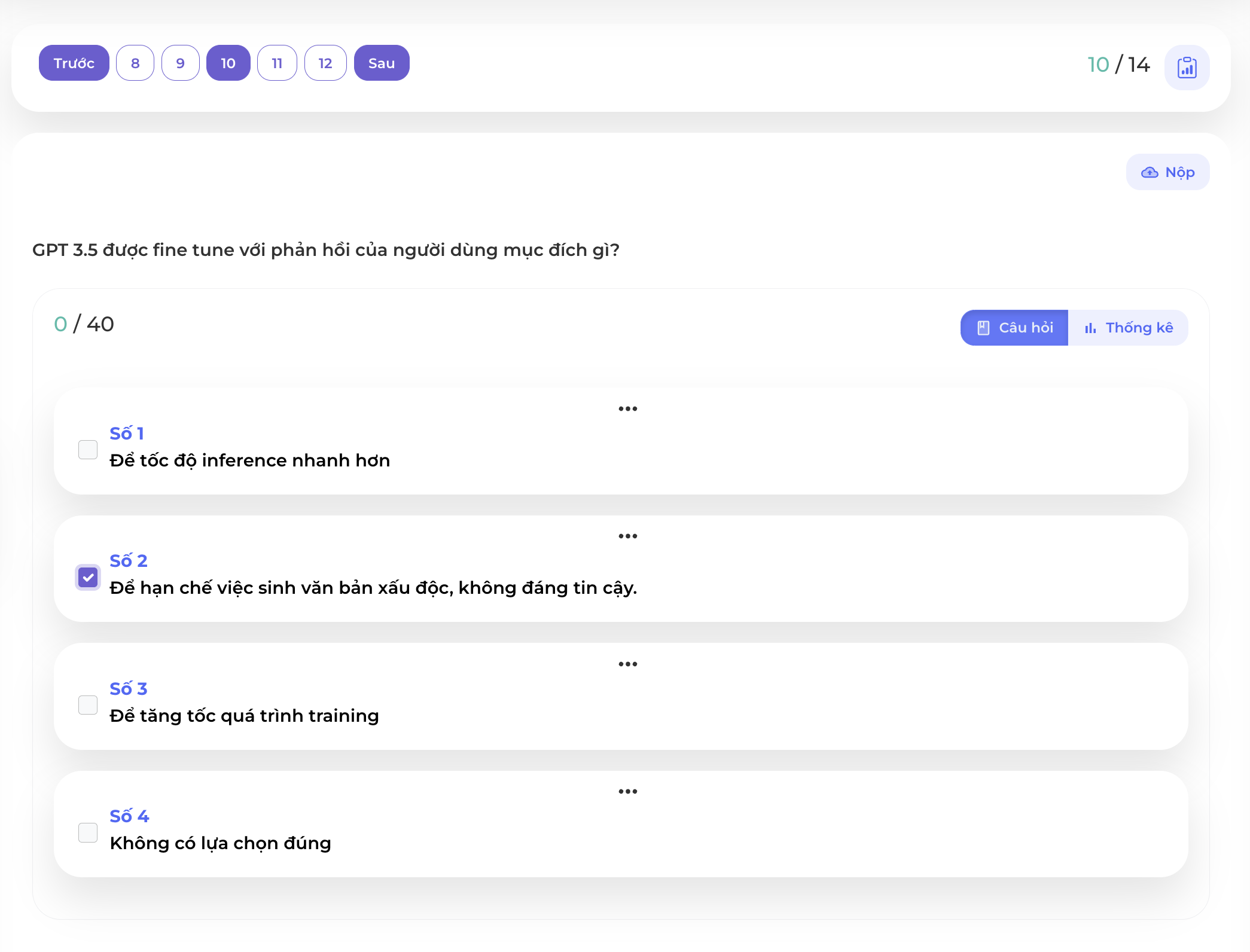
Ngay từ Abstract của IntructionGPT: https://arxiv.org/pdf/2203.02155.pdf đã đề cập đến lý do tại sao mô hình này được xây dựng:

Vấn đề của mô hình ngôn ngữ đó chính là các từ được sinh ra dưới dạng mô hình xác suất nên có xác suất cao các thông tin sinh ra là không chính xác và xấu độc nên các công ty lớn đang rất nỗ lực để cải thiện vấn đề này.
Câu 11
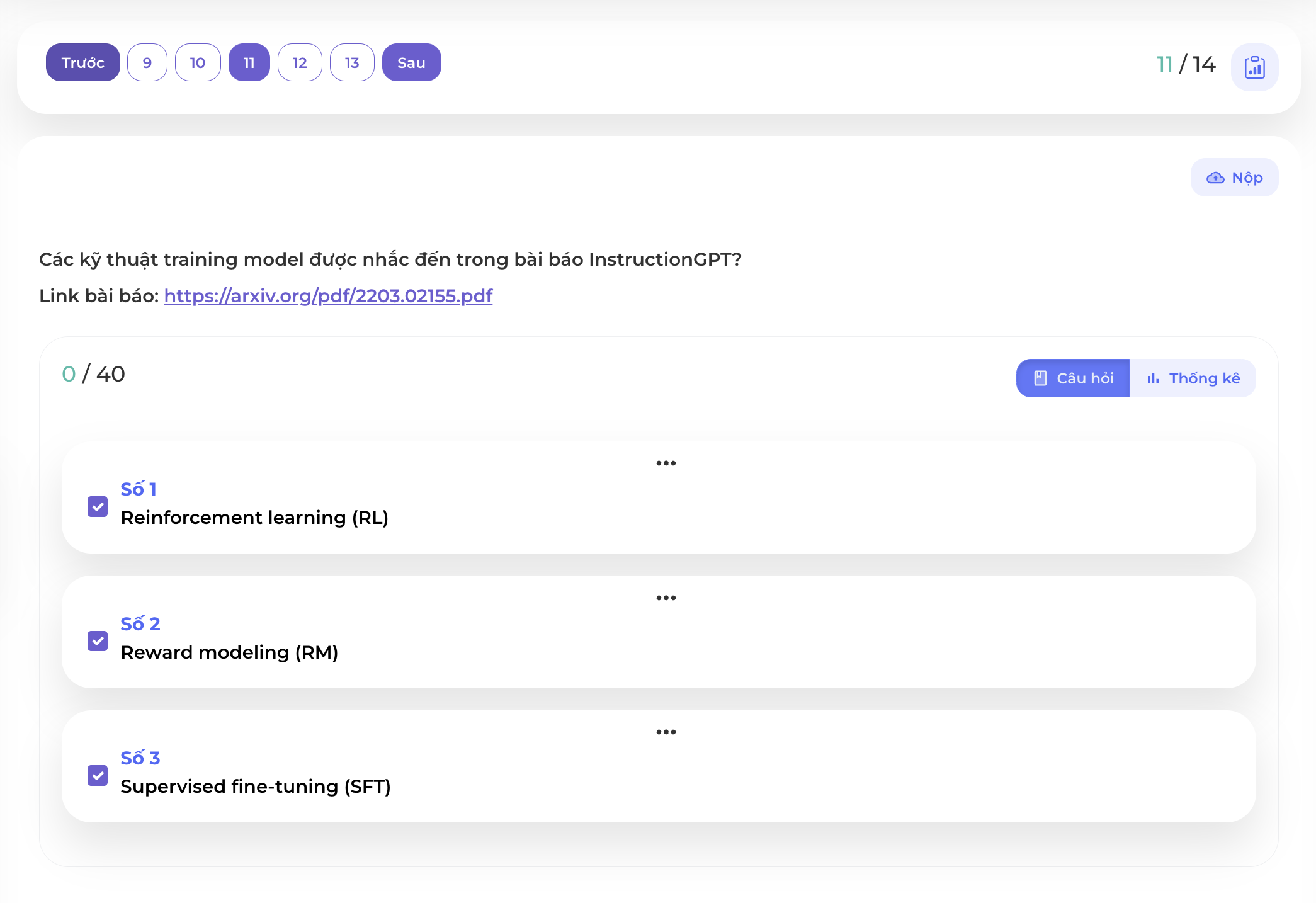
Trong bài báo này cũng đề cập 3 kỹ thuật được training:
- Supervised fine-tuning (SFT): Fine tune GPT-3 bằng các prompt dạng yêu cầu (instruction)
- Reward modeling (RM): Train một mô hình học tăng cường có khả năng ranking các kết quả sinh ra từ mô hình ngôn ngữ
- Reinforcement learning (RL): Finetune ngược lại mô hình ngôn ngữ trên (SFT) bằng mô hình học tăng cường (RM) để điều hướng việc sinh văn bản có kết quả tốt và chính xác hơn.
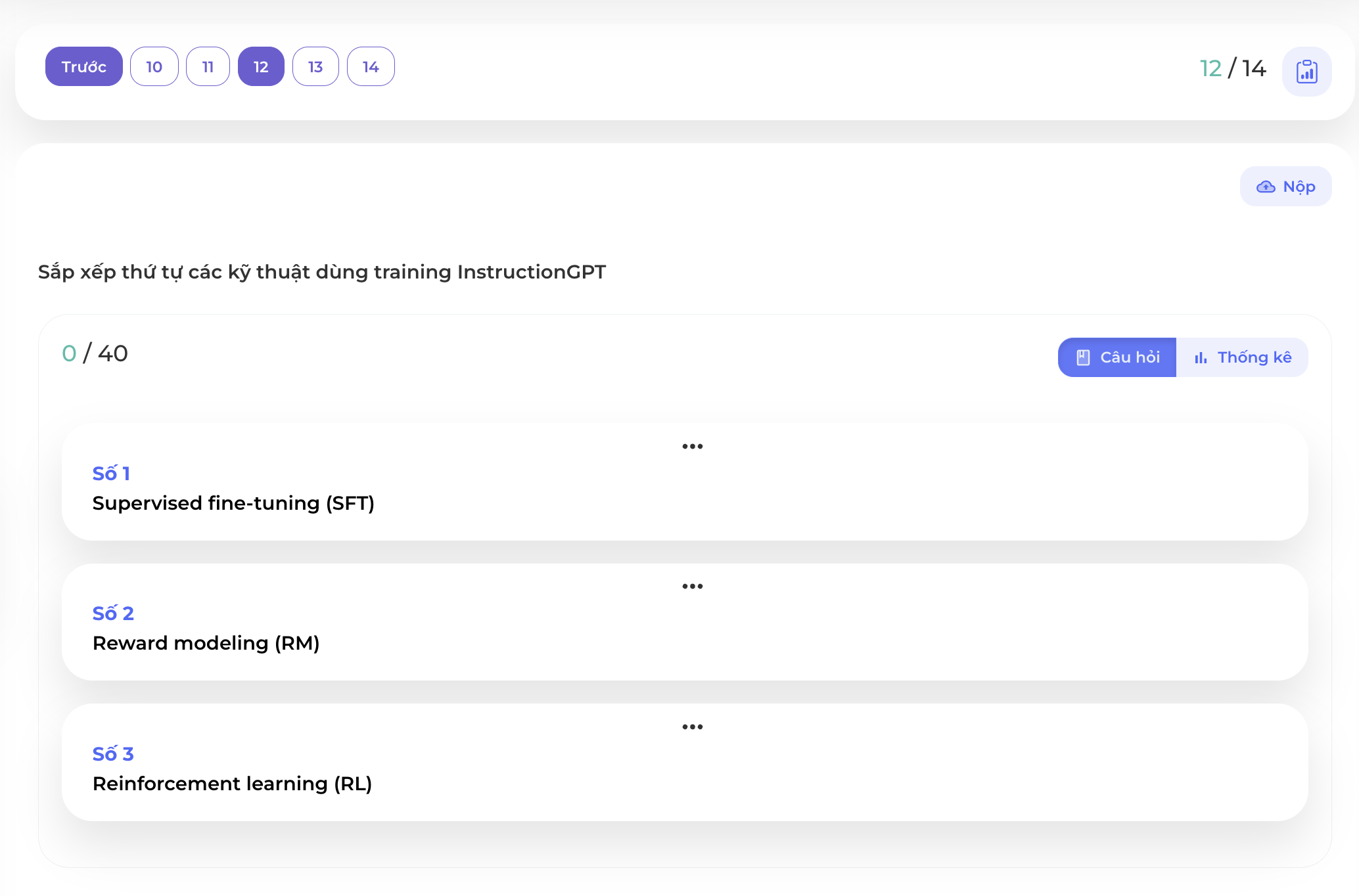
Câu 12
Và thứ tự đúng sẽ là như hình dưới
Câu 13
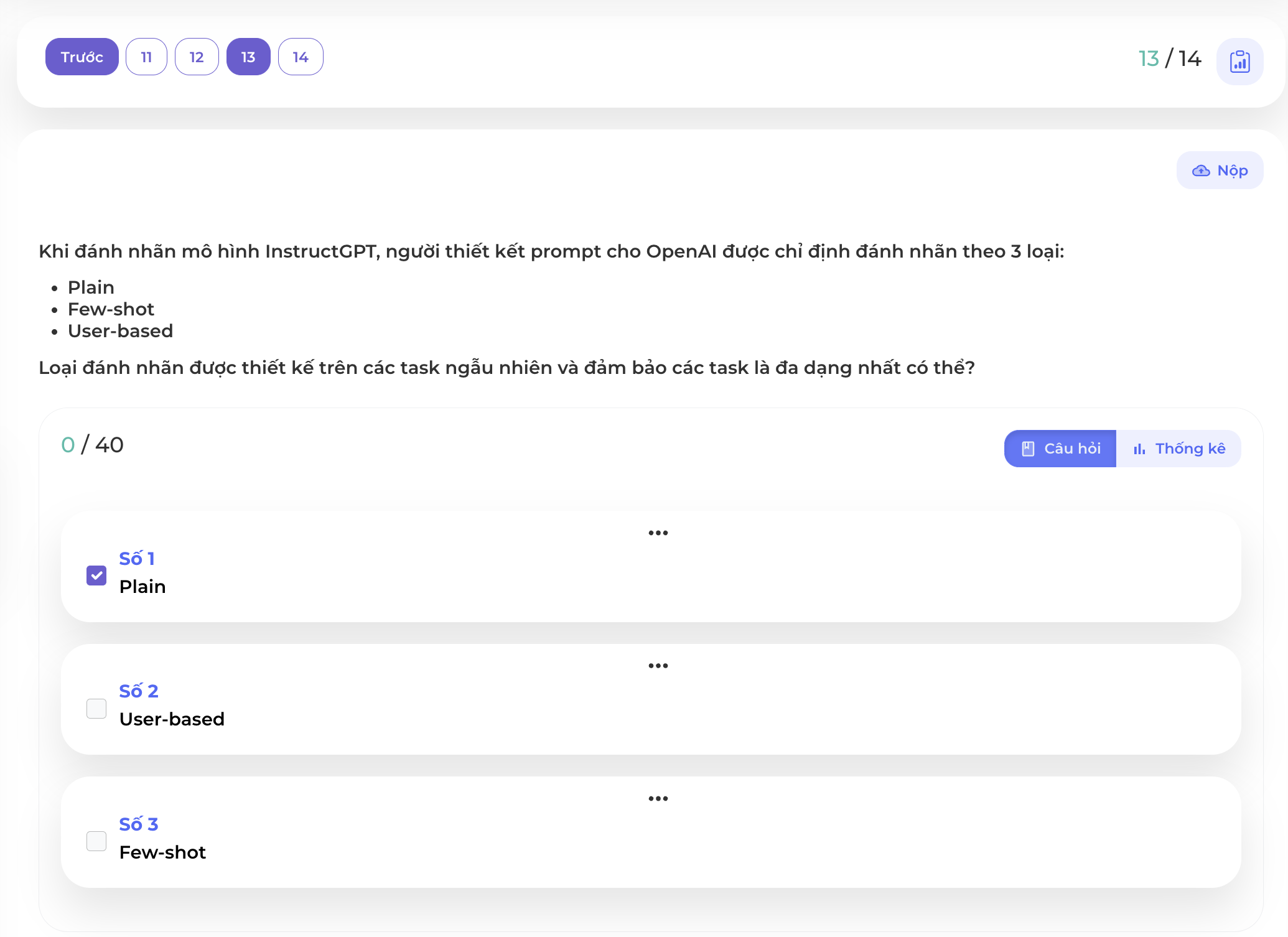
Cách sáng tạo các prompt và đảm bảo tính đa dạng đó chính là Plain

Cho nên bạn có thể thấy OpenAI họ làm rất nhiều liên quan đến Data, cách chuẩn bị các prompt từ việc tự sáng tạo cho đến dựa vào feedback của người dùng.
Câu 14
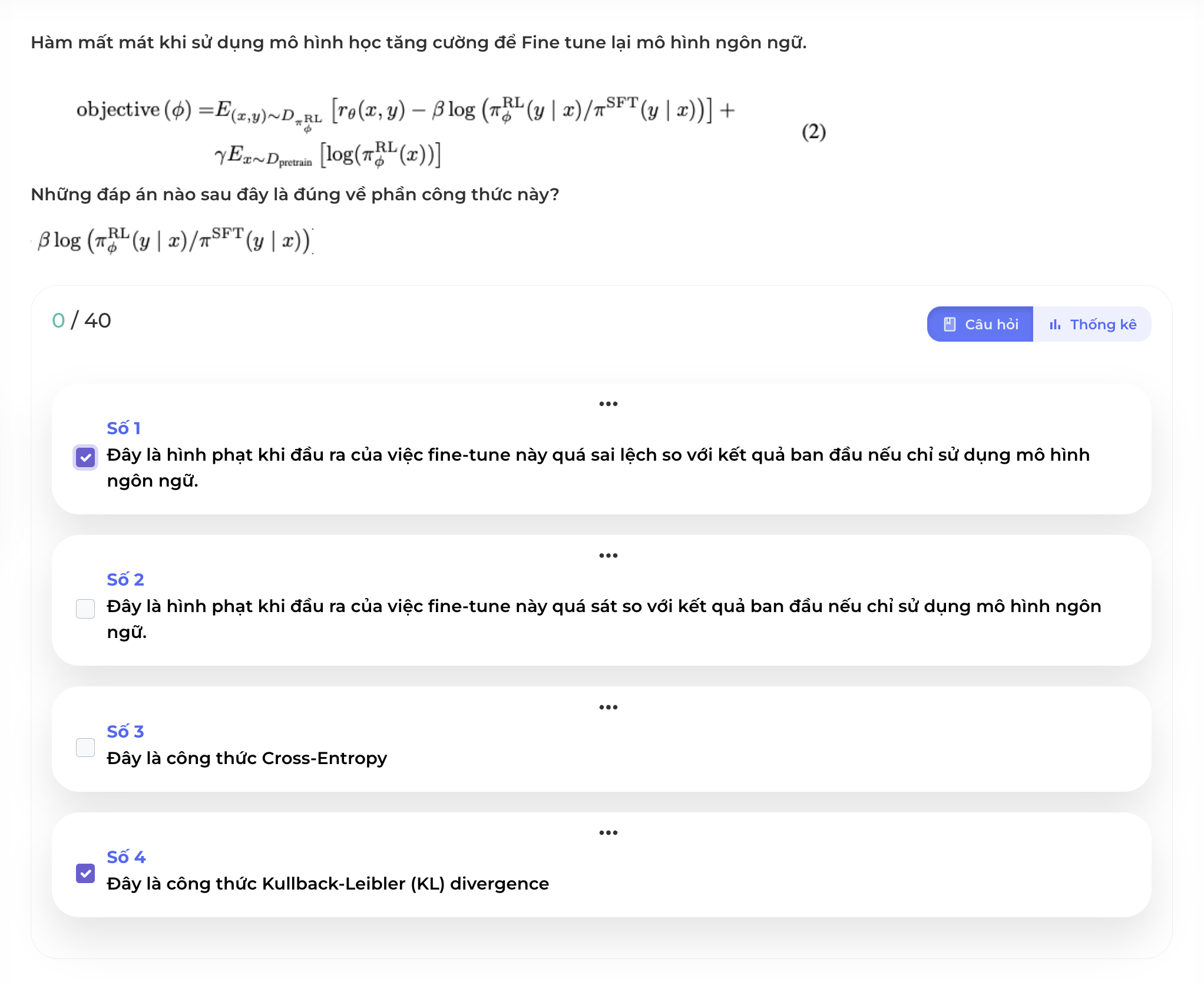
Để tránh việc fine tune mô hình ngôn ngữ bằng mô hình tăng cường đi quá xa so với kết quả khi chỉ dùng mô hình ngôn ngữ, hàm mất mát của việc fine-tune được bổ sung một phần công thức như trong hình để giảm bớt điều này. Đây chính là công thức Kullback-Leibler (KL) divergence thể hiện sự khác nhau giữa phân phối các từ sinh ra từ việc chỉ dùng SFT tức mô hình ngôn ngữ và các từ sinh ra từ việc fine tune hiện tại bằng mô hình học tăng cường RL. Việc phạt nặng hay nhẹ còn được kiểm soát bằng tham số .
Đây là toàn bộ nội dung của cuộc thi ChatGPT, hi vọng bạn đã thu được nhiều kiến thức từ cuộc thi này.
Tham khảo thêm các cuộc thi trong tương lai tại đây.