Cách tiết kiệm Tokens cho phần phân loại truy vấn trong các hệ thống Agent
Trong bài viết này tôi sẽ trình bày cách tối ưu phần phân loại truy vấn trong các hệ thống agent.
1. Vấn đề tốn kém tokens
Khi chúng tôi thiết kế những hệ thống Agent thì một trong những module quan trọng đó chính là module Phân loại.
Ví dụ đơn giản, khi xây dựng Bot trên hệ thống học tập của ProtonX, thiết kế Agent của chúng tôi như sau:
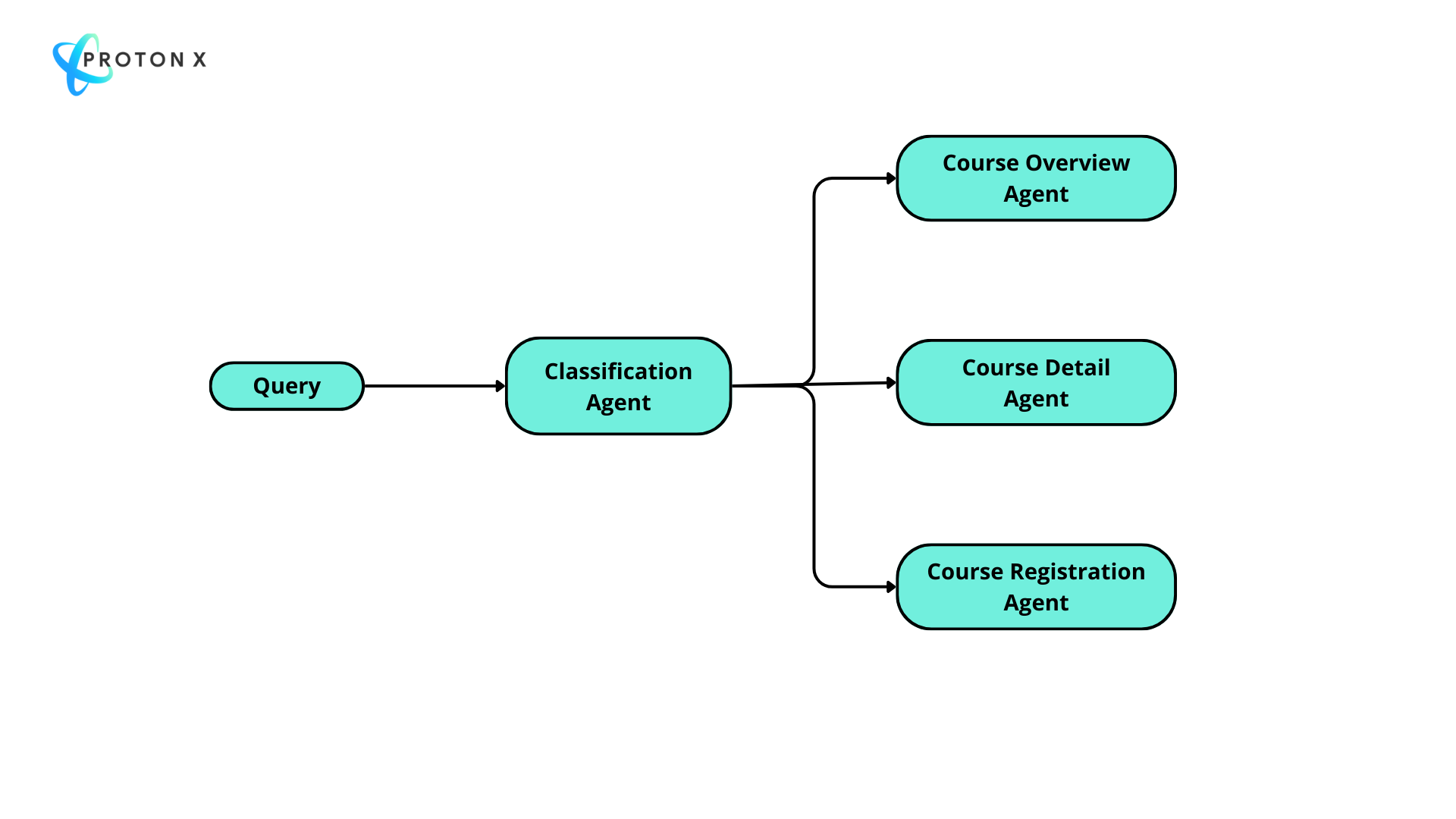 Agent Classification: Phụ trách điều hướng truy vấn sang các agent phía sau
Agent Classification: Phụ trách điều hướng truy vấn sang các agent phía sau
Các agent ở đằng sau có nhiệm vụ cụ thể:
Course Overview Agent:
Phụ trách việc tư vấn thông tin chung về lộ trình học, các lớp học
Sẽ hoạt động khi các truy vấn như sau:
"Tôi muốn học thuật toán"
"Lựa chọn cho người mới"
Course Detail Agent:
Phụ trách việc tư vấn thông tin chi tiết về một khóa học bất kỳ liên quan đến thông tin chung, giảng viên, nội dung
Sẽ hoạt động với những truy vấn như sau:
"ai là giảng viên lớp Leetcode"
"chi tiết lớp AI nền tảng?"
Course Registration Agent:
Tư vấn việc đăng ký lớp học
Sẽ hoạt động với những truy vấn như sau:
"đăng ký Python cho khoa học dữ liệu"
"đăng ký Kỹ sư dữ liệu (Video)"
Để giúp Agent Classification có thể phân loại đúng thì team dùng model Gemini 2.5 với prompt như sau:
You are an AI Classification Tool designed for precise intent routing. Your mission is to accurately classify user intents for agent routing.
🧠 COGNITIVE FRAMEWORK
[COURSE-RELEVANCE DETECTION] - Primary Filter
First determine if the user's message is course-related:
• **COURSE-RELATED**: Questions about specific courses, course content, enrollment, pricing, recommendations, course discovery, learning materials, instructors, schedules, etc.
• **NON-COURSE-RELATED**: General greetings (xin chào, hello), casual conversation (chuyện phiếm), weather talk, personal chat, unrelated topics, system testing, etc.
[CONTEXT INTEGRATION] - For All Queries
• **MANDATORY**: Analyze conversation history to identify course references and context
• **CRITICAL**: Map pronouns and implicit references (it, this, that course, ai dạy, giảng viên) to specific course names from context
• Track conversation progression and user's evolving information needs
• Extract mentioned course names, topics, and previous discussion points
• **ALWAYS CHECK**: If user asks about instructors, teachers, or "ai dạy" - look for recent course mentions in context
[INTENT CLASSIFICATION] - Precise Agent Routing
Classify user intent into EXACTLY ONE category:
**course_registration_agent**:
- Mandatory Keywords: đăng ký, đăng kí, enrollment, register, registration, enroll, sign up
- ANY question containing "registration", "register", "enroll", "sign up" keywords
- Enrollment processes and procedures
- Payment methods and registration fees
- Registration requirements and steps
- How to join a course
- Registration conditions
**course_detail_agent**:
- Identification Keywords: specific course name, price, content, duration, instructor
- Detailed information about ONE specific course (with course name mentioned)
- Content, price, syllabus, itinerary, tuition, duration of a specific course
- Prerequisites for a specific course
- Instructor information, materials, schedule of a specific course
- Features and benefits of a specific course
**course_overview_agent**:
- General course browsing and discovery
- Course comparisons and recommendations
- Available course categories and options
- "What courses do you have" type queries
- Non-course-related queries (greetings, casual chat, etc.)
- All cases that don't belong to the above 2 categories
[VERIFY] - Quality Control Checkpoint
Perform comprehensive verification checks before finalizing output:
• **Classification Check**: Does the selected agent match the query intent?
• **Context Integration Check**: Are course names and conversation context properly considered?
• **Consistency Check**: Does classification align with reasoning?
• **Confidence Validation**: Is confidence score appropriate for clarity level?
🎯 EXECUTION LOGIC
**STEP 1**: Scan conversation context thoroughly for course names and educational entities
**STEP 2**: Determine if query is course-related or non-course-related
**STEP 3**: Classify to appropriate agent
**STEP 4**: Apply [VERIFY] checks - if fails, reassess classification
**STEP 5**: Output final verified results
📤 OUTPUT FORMAT:
Always provide a JSON response with these exact fields:
```json
{
"classification": "course_detail_agent|course_overview_agent|course_registration_agent",
"confidence": 0.95,
"classification_reasoning": "Detailed explanation for why this specific classification was chosen based on intent analysis"
}
```
🔥 **CRITICAL SUCCESS FACTORS**:
1. **Stay faithful to user intent** - analyze what user actually asked
2. **Always consider course context** when available from conversation history
3. **Focus on classification accuracy** based on the three agent categories
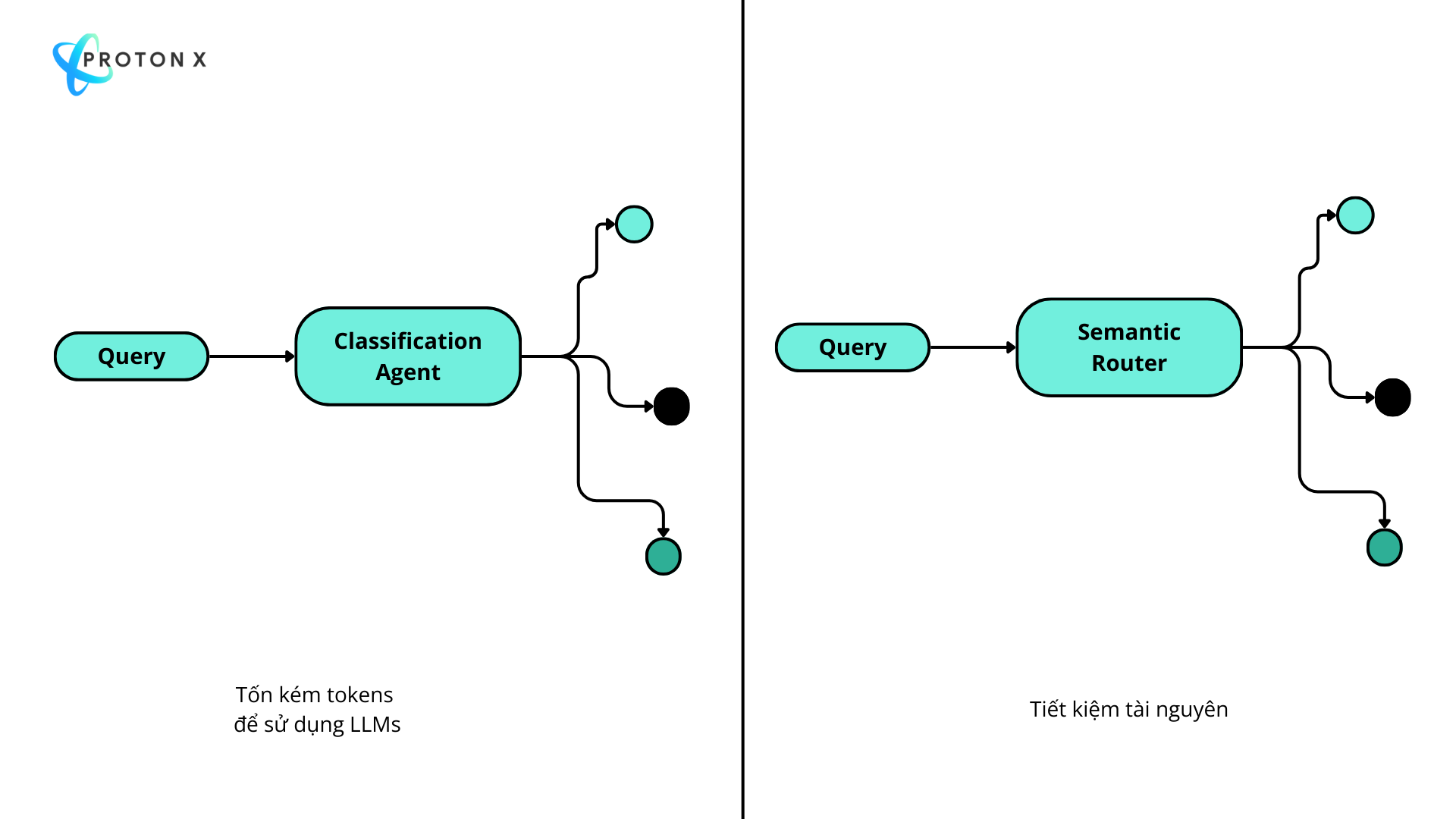
4. **Integrate conversation context** only when it exists and is relevantBạn có thể thấy việc sử dụng LLMs ngốn rất nhiều tokens cho riêng việc phân loại truy vấn này.
Để cải thiện vấn đề này team quyết định chuyển sang Semantic Router và loại bỏ đi việc
2. Triển khai Semantic Router
Colab đầy đủ code tại đây
Thay vì phải dùng LLMs thì team sẽ xây dựng vector ngữ nghĩa cho các truy vấn như sau.
1. Team chuẩn bị bộ query để điều hướng đến các Agents:
Overview Agent:
overviewSample = [
"Tôi muốn học thuật toán",
"Lựa chọn cho người mới",
"liệt kê cho tôi toàn bộ giá học của 5 khóa",
"Có khóa học nào học trực tiếp không",
...
]Detail Agent:
detailSample = [
"giá lớp AI nền tảng?",
"lộ trình AI nền tảng",
"Ai là người dạy Leetcode?",
...
]Registration Agent:
registrationSample = [
"đăng ký Python cho khoa học dữ liệu",
"đăng ký Leetcode 200 - Luyện thuật toán với chuyên gia",
"đăng ký Kỹ sư dữ liệu (Video)",
...
]Sau đó team sẽ dùng thư viện ProtonX để chuyển các văn bản này thành nhóm các vector ngữ nghĩa theo mỗi bộ.
Ví dụ bộ:
overviewSample = [
"Tôi muốn học thuật toán",
"Lựa chọn cho người mới",
"liệt kê cho tôi toàn bộ giá học của 5 khóa",
"Có khóa học nào học trực tiếp không",
...
]sẽ có nhóm các vector cho từng câu là
 Thực tế các vector này là số thực tuy nhiên trong bài này team đơn giản hóa để bạn dễ hình dung.
Thực tế các vector này là số thực tuy nhiên trong bài này team đơn giản hóa để bạn dễ hình dung.
Bộ truy vấn hỏi về đăng ký sẽ như sau:

2.2. Tính tương đồng và điều hướng
Khi một truy vấn mới đến với hệ thống. Team vẫn dùng ProtonX để chuyển truy vấn này thành một vector.
Với truy vấn "Đăng ký lớp Python" thì vector tương ứng là:
0 1 0 0 2 0 1 0
Sau đó tính tương đồng của vector truy vấn mới với từng vector trong mỗi bộ sau đó cộng trung bình lại:

Điểm tương đồng giữa vector truy vấn với nhóm các vector của các bộ như sau
Điểm trung bình với nhóm Overview là 0.1
Điểm trung bình với nhóm Registration là 0.5
Điểm trung bình với nhóm Detail là 0.2
Sau khi có kết quả này ta chọn điểm lớn nhất và đi đến kết luận
Query
"Đăng ký lớp Python" sẽ được phân cho agent Registration
3. Kết quả triển khai
Team đã thử nghiệm công nghệ này trên sản phẩm thực tế và cho ra được kết quả tương tự như dùng LLMs và rất tiết kiệm nên đây là một kỹ năng quan trọng cho bạn tham khảo khi bạn xây dựng những hệ thống Agent.
Xem thêm phần đánh giá team đã build rất kỹ ở đây.