Làm việc với dữ liệu văn bản lớn
Nếu bạn cần phải làm việc 20GB dữ liệu văn bản mà máy tính của bạn chỉ có 4B RAM, chuyện gì sẽ xảy ra nếu bạn sử dụng trực tiếp Python để load file này? Câu trả lời rất đơn giản, máy tính của các bạn sẽ bị tràn RAM.
Một ví dụ về bộ dataset cỡ lớn: PILE, bộ dữ liệu này có 15518009 dòng, rất lớn đúng không?

Vậy giải quyết vấn đề này như thế nào?
Cùng làm quen với khái niệm Memory-mapped file.
Memory Mapping là cơ chế ánh xạ (map) một phần của file hoặc toàn bộ file trên ổ cứng (disk) thành một đoạn trên bộ nhớ. Việc này cho phép chúng ta có thể truy cập vào từng phần của một file lớn như trên thay vì phải load toàn bộ file lên RAM khiến tràn RAM.
1) Thực hành trải nghiệm Memory Mapped Files với pyarrow nhé.
Ví dụ bạn ghi dữ liệu ra một file
with pa.OSFile('example3.dat', 'wb') as f: f.write(b'some example data')
Sau đó bạn tiến hành đọc file này:
mmap = pa.memory_map('example3.dat') mmap.read(4)
Bạn đã đọc một phần của file có nội dung:
b'some'
Với cách đọc từ memory map ở bên trên, thư viện sẽ đọc từng phần của file đã được ánh xạ trên RAM.
Nếu in tất cả ra thì các bạn thấy file đã được chia thành nhiều phần:
for i in range(1, 7): print(mmap.read(i))
Kết quả hiện ra
b's' b'om' b'e e' b'xamp' b'le da' b'ta'
Rõ ràng trong AI cách thức này rất có lợi. Ví dụ khi bạn sử dụng Batch Gradient Descent, bạn sẽ không cần đọc toàn bộ dữ liệu một lúc, thay vào đó ta sẽ load từng phần, xử lý và training.
2) Ứng dụng trong các thư viện AI
Giả sử bạn tải một file dataset từ HuggingFace - Đây chính là một thư viện ứng dụng mạnh mẽ khái niệm bên trên. Xem thêm thư viện này.
from datasets import load_dataset # This takes a few minutes to run, so go grab a tea or coffee while you wait :) data_files = "https://the-eye.eu/public/AI/pile_preliminary_components/PUBMED_title_abstracts_2019_baseline.jsonl.zst" pubmed_dataset = load_dataset("json", data_files=data_files, split="train")
File này dung lượng 19.54GB
print(f"Number of files in dataset : {pubmed_dataset.dataset_size}") size_gb = pubmed_dataset.dataset_size / (1024**3) print(f"Dataset size (cache file) : {size_gb:.2f} GB")
Number of files in dataset : 20979437051 Dataset size (cache file) : 19.54 GB
Sau đó bạn sử dụng thư viện psutil để kiểm tra xem biến pubmed_dataset thực sự đang chiếm bao nhiêu không gian trên RAM?
import psutil # Process.memory_info is expressed in bytes, so convert to megabytes print(f"RAM used: {psutil.Process().memory_info().rss / (1024 * 1024):.2f} MB")
RAM used: 5678.33 MB
Chỉ khoảng hơn 5GB được sử dụng bao gồm cả Python và các biến môi trường khác nên độ lớn biến của chúng ta nhỏ hơn con số này.
Rõ ràng ta nhận ra biến này đại diện cho việc mapping đã được nhắc ở bên trên, luôn luôn load một phần của file.
Dataset Streaming - Làm việc với 1.2 Terabytes dữ liệu mà không cần tải toàn bộ.
1) Giới thiệu về Streaming Dataset
Bộ dữ liệu OSCAR nặng 1.2 Terabytes, mình tin là rất ít người trong chúng ta có ổ cứng đủ để lưu và làm việc với bộ dữ liệu này. Vậy cách giải quyết như thế nào nhỉ?
Câu trả lời: Ta sẽ sử dụng/xây dựng một Streaming Dataset
Cơ chế tương tự Cursor trong MongoDB. Thay vì phải tải dòng một lúc thì khi bạn lặp Cursor đến vị trí dòng nào MongoDB mới tải dòng đó để ta xử lý.
Điều này cực kỳ hữu ích:
- Bạn không phải tải toàn bộ tập dữ liệu về máy
- Bạn muốn thử nghiệm vài samples nhanh
2) Trải nghiệm Streaming Dataset với HuggingFace
Cài đặt HuggingFace Dataset:
!pip install datasets
Sử dụng Dataset dưới dạng Streaming thay vì tải về toàn bộ:
Chú ý tham số streaming=True
from datasets import load_dataset dataset = load_dataset('oscar', "unshuffled_deduplicated_en", split='train', streaming=True) print(next(iter(dataset)))
Kết quả:
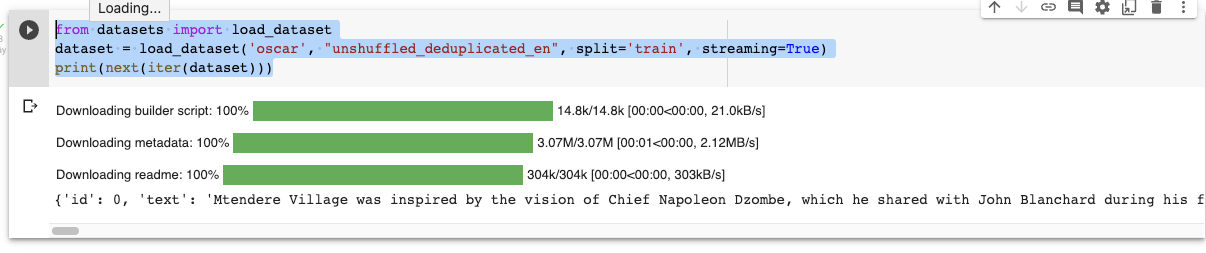
Biến dataaset thuộc lớp IterableDataset cho phép lặp tuần từ qua tất cả các phần tử.
Bạn chỉ thực sự tải dữ liệu khi viết:
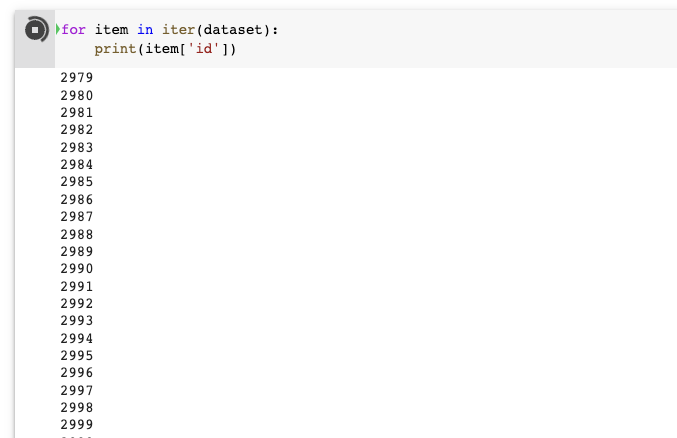
for item in iter(dataset): print(item['id'])
3) Lấy một phần của dữ liệu thế nào
Mình đã làm rất nhiều video về Tensorflow Dataset và cách thức lấy một phần data của HuggingFace Dataset cũng tương tự. Đó chính là hàm take
Bạn lấy 3 phần tử khỏi dataset và chuyển thành mảng.
dataset_head = dataset.take(3) list(dataset_head)
4) Xáo bộ dữ liệu thế nào?
Khi làm AI chắc chắn chúng ta cần phải quan tâm tới việc xáo dữ liệu đúng không? Vậy thì hàm shuffle sẽ giúp bạn làm điều này.
shuffled_dataset = dataset.shuffle(seed=42, buffer_size=1000)
Đây là tính năng tương tự ở bất kỳ một thư viện build dataset nào.
Chúng ta có đầy đủ công cụ hỗ trợ cho bạn tiền xử lý:
- Chia tập train/tập validation
- Hàm map
5) Nguồn tham khảo
- Treaming Dataset: https://huggingface.co/docs/datasets/stream