Video chi tiết bài nói này tại: https://youtu.be/TSQHqxV7Wrc
Slide của bài nói tại đây.
Code: https://github.com/bangoc123/retrieval-backend-with-rag
Tóm tắt hai kỹ thuật:
Semantic Router: Phân loại truy vấn để đưa vào các module tương ứng, nếu truy vấn không cần sử dụng RAG thì đưa trực tiếp sang LLMs.
Reflection: Tóm tắt lại lịch sử chat để tóm tắt và xác định yêu cầu người dùng chính xác thay vì sử dụng các truy vấn gần nhất.
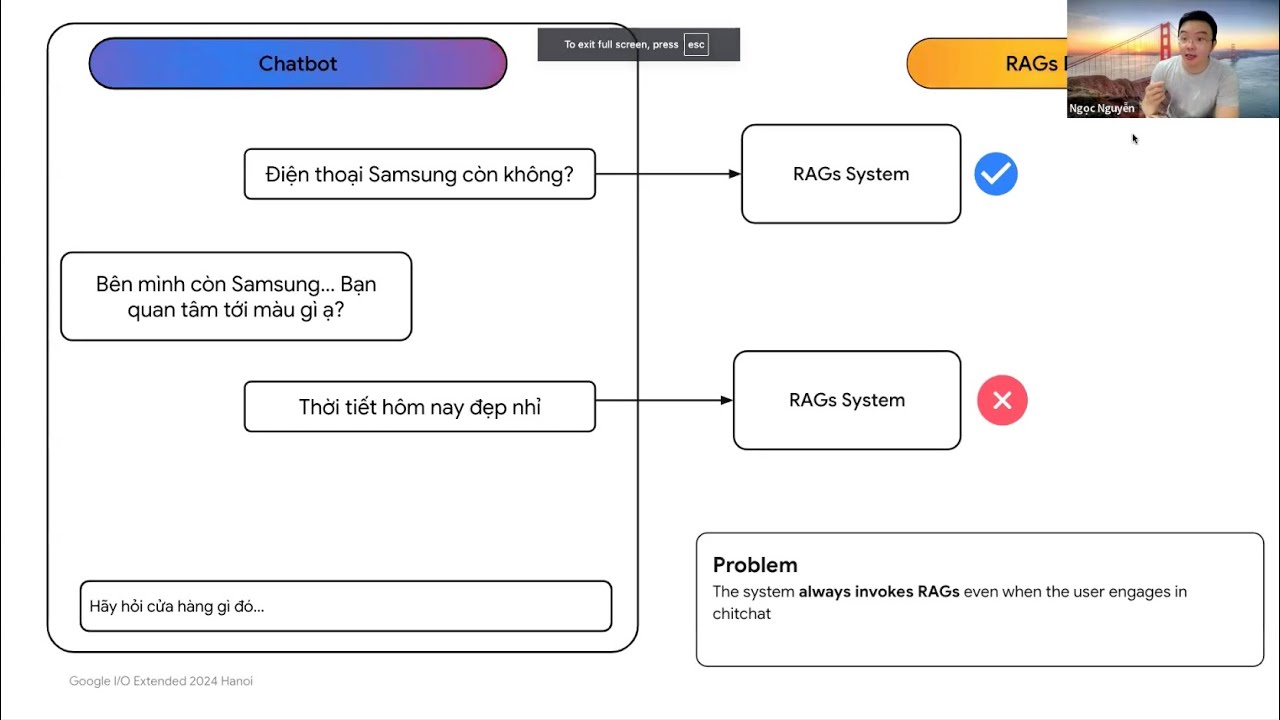
Đào sâu vào Graph RAG phần 1 - Demo tính phân hoạch (Modularity) trên đồ thị
Trong paper của Graph RAG có sử dụng thuật toán Leiden để chia đồ thị thành các cộng đồng nhỏ. Chia càng tốt sẽ tạo ra chất lượng truy vấn tốt.
Chia càng tốt ở đây có nghĩa là nhóm các nút có kết nối với nhau nhiều sẽ được phân hoạch trong cùng một cộng đồng (tính phân hoạch cao) và đảm bảo tính phân hoạch tốt trên tất cả các cộng đồng.
Trong Notebook này team hướng dẫn các bạn tính và so sánh tính phân hoạch của hai đồ thị để giúp bạn dễ tưởng tượng hơn về chỉ số này.
Đường dẫn notebook tại đây.
Tại sao mô hình LLAMA lại sử dụng SwiGLU (Swish-Gated Linear Unit)
Trong bài báo của LLAMA - Open and Efficient Foundation Language Models, một số cải thiện của kiến trúc mô hình so với kiến trúc Transformer thông thường đó chính là hàm activation SwiGLU.
Thay vì sử dụng hàm phi tuyến ReLU như trong bài báo của Transformer thì tác giả sử dụng SwiGLU. Bây giờ chúng ta sẽ giải đáp vì sao LLAMA lại dùng activation này.
Rõ ràng hàm phi tuyến hay được gọi là hàm activation giúp cho mô hình có thể học được những đường cong để xấp xỉ các phân phối dữ liệu phức tạp.
Cấu thành của hàm activation SwiGLU là sự nâng cấp của 2 thành phần:
Hàm activation GLU
Hàm activation Swish
1) GLU - Gated Linear Units
Công thức của GLU:
Cơ chế theo cổng phần nào bạn có thể liên tưởng đến cổng trong mô hình LSTM khi cho phép các cơ chế thu nhận/bỏ thông tin có kiểm soát khi mô hình tính toán. Ví dụ khi đào tạo một câu dài trong ngôn ngữ tự nhiên:
Ví dụ câu:
Anh ấy tên Ngọc rất thích trèo cây, đánh đu, chơi piano và mặc _____??Nhiệm vụ mô hình phải lưu trữ được thông tin ở đầu câu ví dụ từ Anh để có thể điền vào chỗ trống là từ vest thay vì từ váy.
Mô hình hoàn toàn có thể loại bỏ thông tin như rất thích trèo cây vì cho dù nam hoặc nữ đều có thể có sở thích này.
Việc kiểm soát tiếp nhận thông tin bao nhiêu phần % thường được sử dụng thông qua hàm sigmoid vì điều đặc biệt là hàm này sẽ có đầu ra là những giá trị nằm trong đoạn [0, 1] - một cách nôm na, nếu đầu hàm sigmoid này trả về 0.8 tức là ta chỉ cho phép sử dụng 80% thông tin của đầu vào x. Ngoài ra thì sigmoid(Wx+b) là một mạng nơ ron không lớp ẩn có thể học được W và b, một lần nữa tăng việc lựa chọn nơ ron và thông tin nơ ron hữu ích cho hàm mục tiêu của bài toán.
2) Swish activation
Hàm activation Swish cũng gần như tương tự với hàm GELU tuy nhiên tham số để học chỉ còn duy nhất tham số beta.
Mục tiêu vẫn là kiểm soát thông tin đầu vào. Thực nghiệm cho thấy hàm activation này cho khả năng hội tụ tốt hơn so với các hàm activation thông thường như RELU.
3) Kết hợp Swish và GLU ta có SwiGLU.
SwiGLU nổi tiếng khi được sử dụng trong mô hình ngôn ngữ lớn PALM và LLAMA. Trong kiến trúc của mô hình LLAMA thì SwishGLU là một trong 3 điểm cải tiến Meta sử dụng để đào tạo mô hình ngôn ngữ lớn tương tự họ GPT của OpenAI.
SwiGLU tạo ra một sự phối hợp phức tạp hơn GLU và Swish bằng việc cho thêm bộ tham số học được bao gồm bộ W và b và bộ V, c giúp tăng khả năng của hàm activation, hay nói cách khác sẽ học được nhiều hơn việc sử dụng đầu vào x. Việc thêm bộ tham số để học xảy ra thông thường trong học sâu.
Tuy nhiên cơ chế cổng vẫn là cốt lõi làm nên thành công của hàm activation này.
4) Thực nghiệm hiệu năng của SwiGLU
Theo bài báo GLU Variants Improve Transformer,
 Với bài toán segment-filling thì hàm activation này cho điểm Perplexity là thấp nhất.
Với bài toán segment-filling thì hàm activation này cho điểm Perplexity là thấp nhất.
Perplexity là thang đo hiệu quả của một mô hình ngôn ngữ. Perplexity càng thấp thì model càng có chất lượng cao.

Rõ ràng ta nhận thấy trong một số bài toán của GLUE Language-Understanding Benchmark thì SwiGLU có kết quả tốt nhất, đây cũng chính là lý do hàm này được tác giả của LLAMA lựa chọn.
5) Một số ưu thế của hàm activation này
Cơ chế cổng lựa chọn thông tin giúp cho mô hình có khả năng lựa chọn các nơ ron có đóng góp cao cho kết quả của bài toán
Trái với RELU là hàm đơn điệu, SwiGLU là hàm không đơn điệu cho phép mô hình xấp xỉ được các quan hệ phi tuyến phức tạp
Ngoài ra thì hàm này làm cho bề mặt đồ thị hàm mất mát mịn hơn làm tăng khả năng hội tụ của mô hình.
Trên đây là cách SwiGLU hoạt động và các lý do để hàm này được sử dụng nhiều hơn trong các bài toán AI gần đây.
Nguồn tham khảo:
Ước lượng giá trị mất mát tối ưu dựa vào số lượng tham số
1) Khi bạn làm việc đủ lâu với một mô hình, bạn sẽ nắm được rất nhiều thông số quan trọng để tăng tốc trong những lần training tiếp theo
Có một điều rất thú vị mà có thể bạn quan tâm, khi bạn làm việc với một mô hình đủ lâu, bạn có thể hình thành mối tương quan giữa số lượng tham số của mô hình và giá trị mất mát tối ưu.
Trong năm qua, đội ngũ ProtonX đã train rất nhiều mô hình cho Studio. sử dụng GPT2 - Medium với 345 triệu tham số với rất nhiều domain khác nhau, từ tuyển dụng cho đến công thức nấu ăn rồi viết bài marketing, chuẩn SEO, vv.
Với những domain cụ thể, team có những con số tương đối chính xác để dự đoán được hiệu suất của mô hình. Ví dụ như sau:
- Với domain đơn giản như mô tả công việc (JD), chỉ cần khoảng 100.000 văn bản trở lên, bạn đã có thể tạo ra được một mô hình có khả năng sinh được ra miêu tả đủ dùng.
Đây là output cho vị trí phân tích dữ liệu:
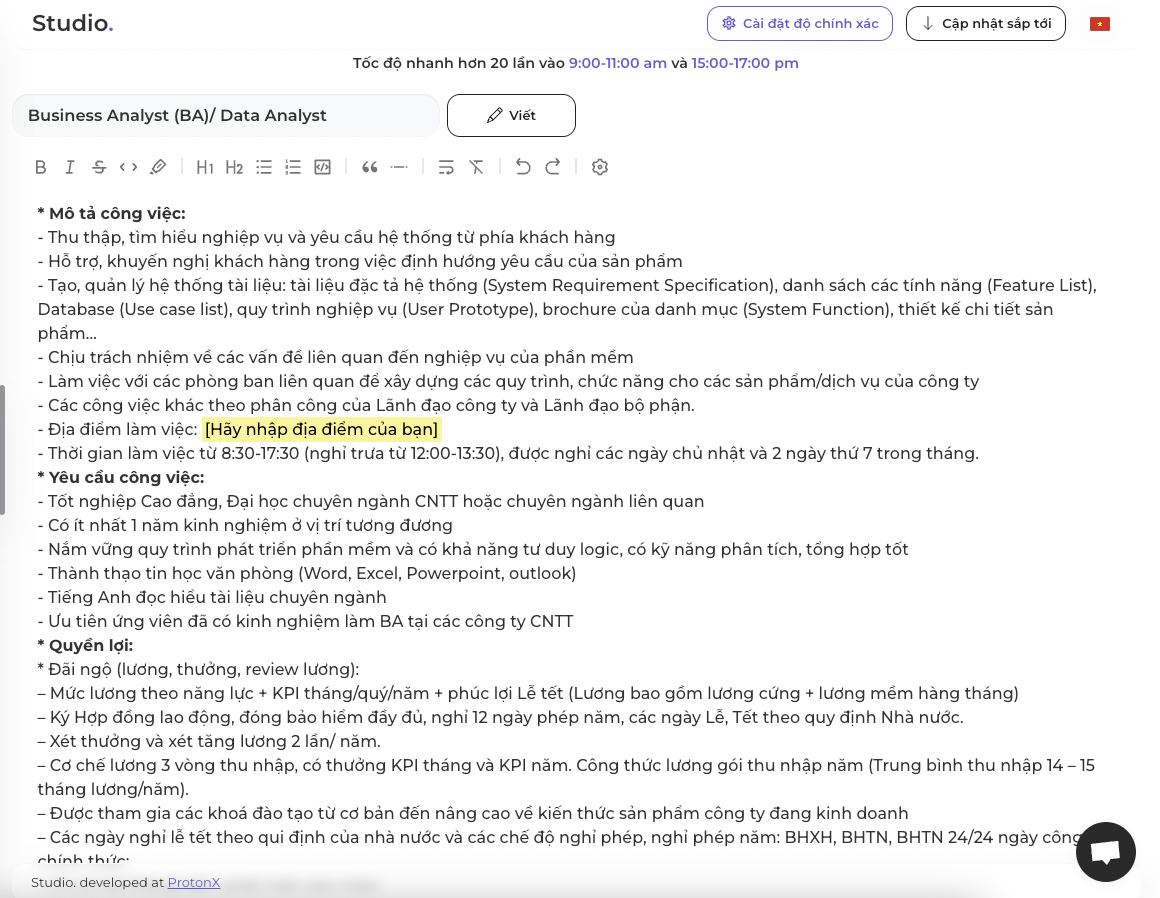
Theo người dùng phản hồi thì mô hình hiện tại đang hỗ trợ người dùng 50% trong việc viết miêu tả, tức là 50% còn lại người dùng cần chỉnh sửa và nhập các thông tin cá nhân như quyền lợi ứng viên, địa chỉ công ty.
2) Ước lượng giá trị mất mát tối ưu dựa vào số lượng tham số của mô hình
Gần đây team có đọc nghiên cứu Scaling Laws for Neural Language Models thì đã liên hệ trực tiếp quá trình training của team thì có một số nhận định khá tương đồng.
Có 3 luật quan trọng trong bài báo này nhưng trong bài viết này mình sẽ chỉ nhắc đến quy luật đầu tiên mà họ rút ra.
Với mô hình giới hạn tham số, giá trị mất mát tối ưu (hội tụ tốt) với lượng dataset đủ lớn sẽ xấp xỉ theo công thức sau:
Với và là hai giá trị cố định
- chính là giá trị mất mát tối ưu
- : số lượng tham số của mô hình
Áp dụng vào bài toán của team:
Hiện tại team có hơn 200.000 miêu tả công việc, nếu áp dụng công thức này thì giá trị mất mát hợp lý sẽ là:
Con số này khá thú vị, đó chính là con số mà team rất hay gặp trong khoảng training 7-10 epochs đầu tiên, vậy là nhận định này đã đúng với những gì thực tế diễn ra.
Ví dụ đây là epoch số 6 mà team đào tạo
'loss': 2.6251, 'learning_rate': 9.333333333333334e-06, 'epoch': 6.0}
30%|████████████████████████▉ | 37806/126020 [11:41:23<24:58:47, 1.02s/it]***** Running Evaluation *****
Num examples = 378055
Batch size = 8
{'eval_loss': 2.65189266204834, 'eval_runtime': 571.2631, 'eval_samples_per_second': 661.788, 'eval_steps_per_second': 20.682, 'epoch': 6.0}
30%|████████████████████████▉ | 37806/126020 [11:50:54<24:58:47, 1.02s/it]
Giá trị rất sát với công thức trên.
Tất nhiêu theo đánh giá của team, công thức này sẽ đúng hơn nữa khi dataset lớn hơn khoảng 1 triệu bản ghi, tuy nhiên là một trong những thước đo rất quan trọng giúp bạn có thể ước lượng được điểm dừng sớm.
Team rất mong bạn có thể tham khảo công thức này để tiết kiệm thời gian và có những insight quan trong mà mình làm việc mỗi ngày.
Làm việc với dữ liệu văn bản lớn
Nếu bạn cần phải làm việc 20GB dữ liệu văn bản mà máy tính của bạn chỉ có 4B RAM, chuyện gì sẽ xảy ra nếu bạn sử dụng trực tiếp Python để load file này? Câu trả lời rất đơn giản, máy tính của các bạn sẽ bị tràn RAM.
Một ví dụ về bộ dataset cỡ lớn: PILE, bộ dữ liệu này có 15518009 dòng, rất lớn đúng không?

Vậy giải quyết vấn đề này như thế nào?
Cùng làm quen với khái niệm Memory-mapped file.
Memory Mapping là cơ chế ánh xạ (map) một phần của file hoặc toàn bộ file trên ổ cứng (disk) thành một đoạn trên bộ nhớ. Việc này cho phép chúng ta có thể truy cập vào từng phần của một file lớn như trên thay vì phải load toàn bộ file lên RAM khiến tràn RAM.
1) Thực hành trải nghiệm Memory Mapped Files với pyarrow nhé.
Ví dụ bạn ghi dữ liệu ra một file
with pa.OSFile('example3.dat', 'wb') as f: f.write(b'some example data')
Sau đó bạn tiến hành đọc file này:
mmap = pa.memory_map('example3.dat') mmap.read(4)
Bạn đã đọc một phần của file có nội dung:
b'some'
Với cách đọc từ memory map ở bên trên, thư viện sẽ đọc từng phần của file đã được ánh xạ trên RAM.
Nếu in tất cả ra thì các bạn thấy file đã được chia thành nhiều phần:
for i in range(1, 7): print(mmap.read(i))
Kết quả hiện ra
b's' b'om' b'e e' b'xamp' b'le da' b'ta'
Rõ ràng trong AI cách thức này rất có lợi. Ví dụ khi bạn sử dụng Batch Gradient Descent, bạn sẽ không cần đọc toàn bộ dữ liệu một lúc, thay vào đó ta sẽ load từng phần, xử lý và training.
2) Ứng dụng trong các thư viện AI
Giả sử bạn tải một file dataset từ HuggingFace - Đây chính là một thư viện ứng dụng mạnh mẽ khái niệm bên trên. Xem thêm thư viện này.
from datasets import load_dataset # This takes a few minutes to run, so go grab a tea or coffee while you wait :) data_files = "https://the-eye.eu/public/AI/pile_preliminary_components/PUBMED_title_abstracts_2019_baseline.jsonl.zst" pubmed_dataset = load_dataset("json", data_files=data_files, split="train")
File này dung lượng 19.54GB
print(f"Number of files in dataset : {pubmed_dataset.dataset_size}") size_gb = pubmed_dataset.dataset_size / (1024**3) print(f"Dataset size (cache file) : {size_gb:.2f} GB")
Number of files in dataset : 20979437051 Dataset size (cache file) : 19.54 GB
Sau đó bạn sử dụng thư viện psutil để kiểm tra xem biến pubmed_dataset thực sự đang chiếm bao nhiêu không gian trên RAM?
import psutil # Process.memory_info is expressed in bytes, so convert to megabytes print(f"RAM used: {psutil.Process().memory_info().rss / (1024 * 1024):.2f} MB")
RAM used: 5678.33 MB
Chỉ khoảng hơn 5GB được sử dụng bao gồm cả Python và các biến môi trường khác nên độ lớn biến của chúng ta nhỏ hơn con số này.
Rõ ràng ta nhận ra biến này đại diện cho việc mapping đã được nhắc ở bên trên, luôn luôn load một phần của file.
Dataset Streaming - Làm việc với 1.2 Terabytes dữ liệu mà không cần tải toàn bộ.
1) Giới thiệu về Streaming Dataset
Bộ dữ liệu OSCAR nặng 1.2 Terabytes, mình tin là rất ít người trong chúng ta có ổ cứng đủ để lưu và làm việc với bộ dữ liệu này. Vậy cách giải quyết như thế nào nhỉ?
Câu trả lời: Ta sẽ sử dụng/xây dựng một Streaming Dataset
Cơ chế tương tự Cursor trong MongoDB. Thay vì phải tải dòng một lúc thì khi bạn lặp Cursor đến vị trí dòng nào MongoDB mới tải dòng đó để ta xử lý.
Điều này cực kỳ hữu ích:
- Bạn không phải tải toàn bộ tập dữ liệu về máy
- Bạn muốn thử nghiệm vài samples nhanh
2) Trải nghiệm Streaming Dataset với HuggingFace
Cài đặt HuggingFace Dataset:
!pip install datasets
Sử dụng Dataset dưới dạng Streaming thay vì tải về toàn bộ:
Chú ý tham số streaming=True
from datasets import load_dataset dataset = load_dataset('oscar', "unshuffled_deduplicated_en", split='train', streaming=True) print(next(iter(dataset)))
Kết quả:
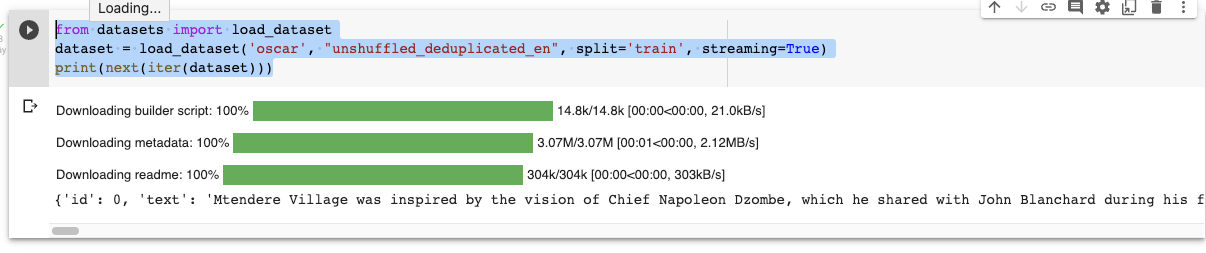
Biến dataaset thuộc lớp IterableDataset cho phép lặp tuần từ qua tất cả các phần tử.
Bạn chỉ thực sự tải dữ liệu khi viết:
for item in iter(dataset): print(item['id'])
3) Lấy một phần của dữ liệu thế nào
Mình đã làm rất nhiều video về Tensorflow Dataset và cách thức lấy một phần data của HuggingFace Dataset cũng tương tự. Đó chính là hàm take
Bạn lấy 3 phần tử khỏi dataset và chuyển thành mảng.
dataset_head = dataset.take(3) list(dataset_head)
4) Xáo bộ dữ liệu thế nào?
Khi làm AI chắc chắn chúng ta cần phải quan tâm tới việc xáo dữ liệu đúng không? Vậy thì hàm shuffle sẽ giúp bạn làm điều này.
shuffled_dataset = dataset.shuffle(seed=42, buffer_size=1000)
Đây là tính năng tương tự ở bất kỳ một thư viện build dataset nào.
Chúng ta có đầy đủ công cụ hỗ trợ cho bạn tiền xử lý:
- Chia tập train/tập validation
- Hàm map
5) Nguồn tham khảo
- Treaming Dataset: https://huggingface.co/docs/datasets/stream