Phần 4 - Giải thích chi tiết kiến trúc mô hình YOLO
Trước tiên để hiểu được kiến trúc này bạn cần có kiến thức về mạng CNN. Xem thêm chi tiết về mạng này tại đây.
Kiến trúc của mô hình YOLO sử dụng các lớp tích chập (Convolution), lớp MaxPooling để đưa từ ảnh đầu vào có chiều (448, 448, 3) và chiều (7, 7, 30). Tại sao kết quả có chiều này thì mình đã miêu tả rất rõ ràng trong bài viết phần 2.

1) Cách tính chiều đầu ra của lớp tích chập
Lớp tích chập là gì được miêu tả chi tiết ở đây.
1.1) Tính toán chiều dài, chiều cao, số kênh của đầu ra


1.2) Diễn giải công thức
Tính chiều đầu ra
Chiều dài
chiều dài đầu ra = [ (chiều dài đầu vào) - (chiều dài của bộ lọc) + 2 x (số padding) ] / (bước nhảy) + 1
Chiều cao
chiều cao đầu ra = [ ( chiều cao đầu vào) - (chiều cao của bộ lọc) + 2 x (số padding) ] / (bước nhảy) + 1
Số kênh đầu ra = Số bộ lọc
2) Cách tính chiều đầu ra của lớp Maxpooling
Xem chi tiết cách lớp Maxpooling hoạt động tại đây.

Tính chiều đầu ra
Thông thường chiều của bộ lọc của maxpool là (2, 2) làm cho chiều dài và rộng của đầu vào đều giảm đi 2.
Trong hình bạn thấy chiều của đầu vào là (4,4) và chiều đầu ra là (2, 2).
3) Kiến trúc của mô hình YOLO
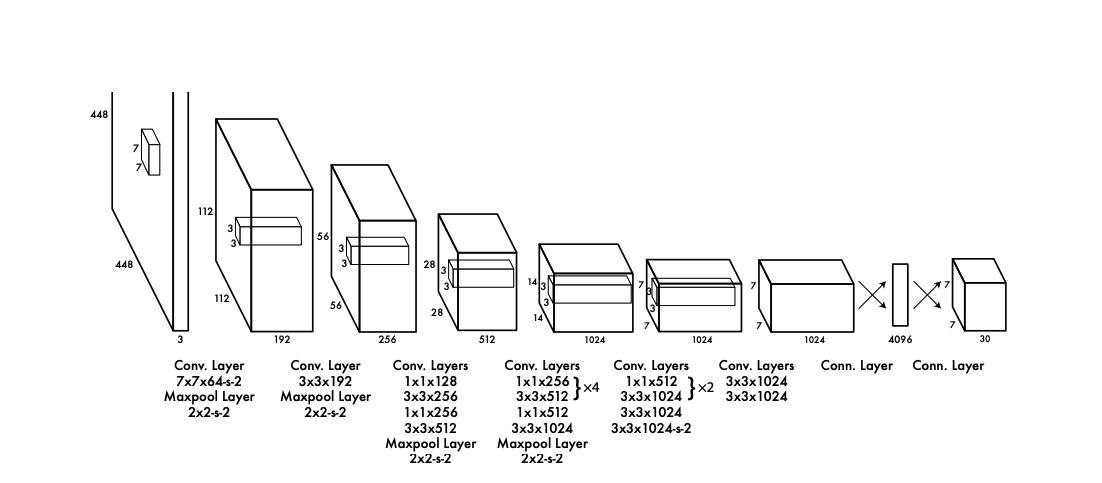 Nguồn ảnh
Nguồn ảnhVí dụ ở lớp tích chập đầu tiên:
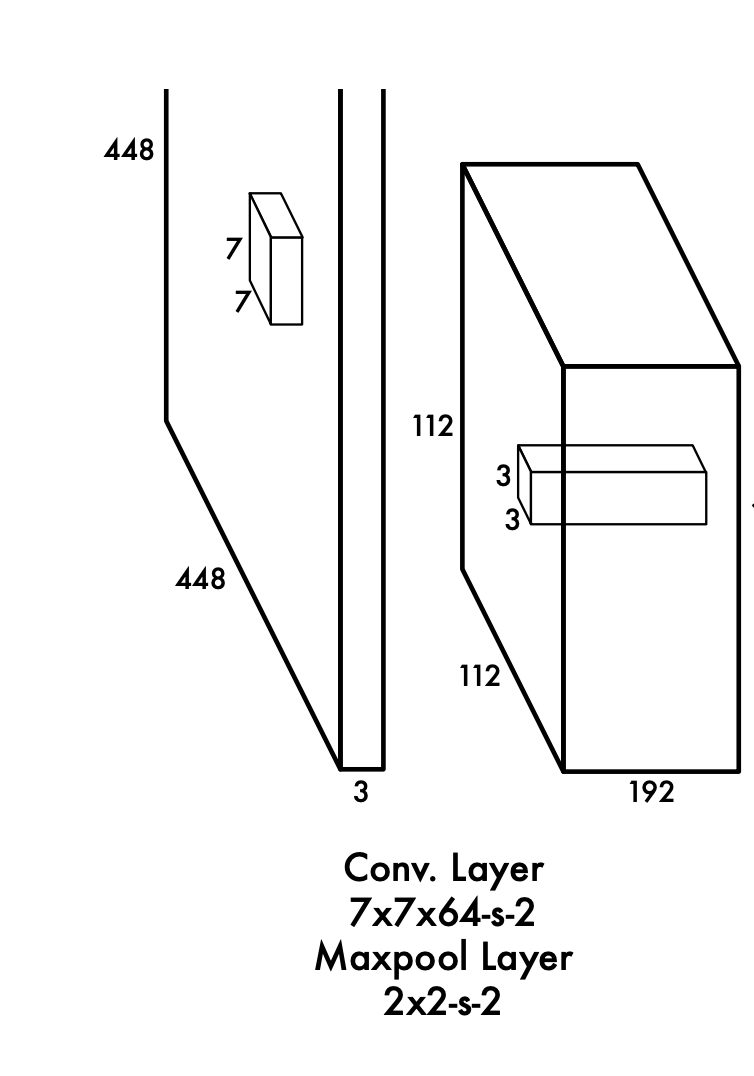
Đầu vào (448, 448, 3)
Thực hiện phép tích chập với 64 bộ lọc cỡ (7,7). Số bước nhảy S=2
Áp dụng công thức để tính chiều của đầu ra
Chiều dài đầu ra = [ (chiều dài đầu vào) - (chiều dài của bộ lọc) + 2 x (số padding) ] / (bước nhảy) = (448 - 7 + 2 x 3) // 2 + 1 = 224
Chiều cao đầu ra = [ ( chiều cao đầu vào) - (chiều cao của bộ lọc) + 2 x (số padding) ] / (bước nhảy) + 1 = (448 - 7 + 2 x 3) // 2 + 1 = 224
Số kênh của đầu ra = Số bộ lọc = 64
Vậy kết luận đầu ra có chiều là (224, 224, 64)
Ở lớp Maxpool tiếp theo:
Đầu vào (224, 224, 64)
Thực hiện phép Maxpool với chiều (2,2) và số bước nhảy là 2
Chiều dài đầu ra: 224 / 2 = 112
Chiều cao đầu ra: 224 / 2 = 112
Vậy kết luận đầu ra có chiều là (112, 112, 64)
Ở lớp tích chập tiếp theo:
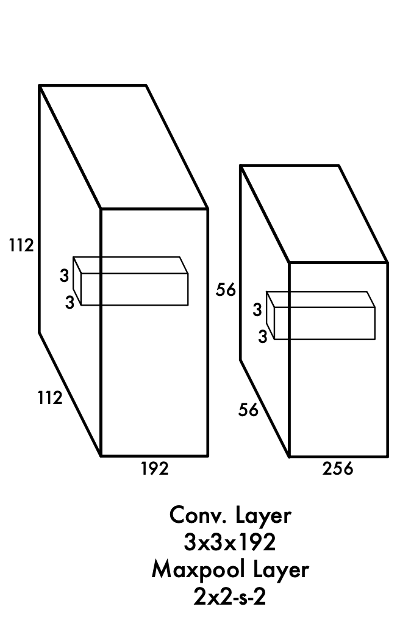
Đầu vào (112, 112, 64)
Thực hiện phép tích chập với 192 bộ lọc cỡ (3, 3). Số bước nhảy S=1
Chiều dài đầu ra = [ (chiều dài đầu vào) - (chiều dài của bộ lọc) + 2 x (số padding) ] / (bước nhảy) = (112 - 3 + 2 x 1) // 1 + 1 = 112
Chiều cao đầu ra = [ ( chiều cao đầu vào) - (chiều cao của bộ lọc) + 2 x (số padding) ] / (bước nhảy) + 1 = (112 - 3 + 2 x 1) // 1 + 1 = 112
Số kênh của đầu ra = Số bộ lọc = 192
Vậy kết luận đầu ra có chiều là (112, 112, 192)
Phân tích lớp tích chập dùng bộ lọc (1, 1):

Thường bộ lọc (1, 1) dùng để giữ chiều dài, chiều cao và thay đổi số kênh của feature map
Đầu vào (56, 56, 256)
Thực hiện phép tích chập với 128 bộ lọc cỡ (1, 1). Số bước nhảy S=1
Chiều dài đầu ra = [ (chiều dài đầu vào) - (chiều dài của bộ lọc) + 2 x (số padding) ] / (bước nhảy) = (56 - 3 + 2 x 1) // 1 + 1 = 56
Chiều cao đầu ra = [ ( chiều cao đầu vào) - (chiều cao của bộ lọc) + 2 x (số padding) ] / (bước nhảy) + 1 = (56 - 3 + 2 x 1) // 1 + 1 = 56
Số kênh của đầu ra = Số bộ lọc = 128
Vậy kết luận đầu ra có chiều là (56, 56, 128)
Lớp cuối cùng:

Đầu vào (4096,)
Thực hiện một lớp nhân ma trận + hàm phí tuyển để tạo ra chiều (1470,). Chiều này tương đồng với chiều (7, 7, 30) đã được nhắc tới trong phần 2.
3) Cách thức lập trình mô hình
Trong bài này chúng ta sẽ sử dụng Pytorch để lập trình mô hình
Chi tiết mô hình được lập trình theo hình vẽ bên trên
import torch
import torch.nn as nn
from torchvision.models import resnet50, ResNet50_Weights
class YOLOv1(nn.Module):
def __init__(self):
super().__init__()
self.depth = B * 5 + C
layers = [
nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3), # Conv 1
nn.LeakyReLU(negative_slope=0.1),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(64, 192, kernel_size=3, padding=1), # Conv 2
nn.LeakyReLU(negative_slope=0.1),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(192, 128, kernel_size=1), # Conv 3
nn.LeakyReLU(negative_slope=0.1),
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.LeakyReLU(negative_slope=0.1),
nn.Conv2d(256, 256, kernel_size=1),
nn.LeakyReLU(negative_slope=0.1),
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.LeakyReLU(negative_slope=0.1),
nn.MaxPool2d(kernel_size=2, stride=2)
]
for i in range(4): # Conv 4
layers += [
nn.Conv2d(512, 256, kernel_size=1),
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.LeakyReLU(negative_slope=0.1)
]
layers += [
nn.Conv2d(512, 512, kernel_size=1),
nn.Conv2d(512, 1024, kernel_size=3, padding=1),
nn.LeakyReLU(negative_slope=0.1),
nn.MaxPool2d(kernel_size=2, stride=2)
]
for i in range(2): # Conv 5
layers += [
nn.Conv2d(1024, 512, kernel_size=1),
nn.Conv2d(512, 1024, kernel_size=3, padding=1),
nn.LeakyReLU(negative_slope=0.1)
]
layers += [
nn.Conv2d(1024, 1024, kernel_size=3, padding=1),
nn.LeakyReLU(negative_slope=0.1),
nn.Conv2d(1024, 1024, kernel_size=3, stride=2, padding=1),
nn.LeakyReLU(negative_slope=0.1),
]
for _ in range(2): # Conv 6
layers += [
nn.Conv2d(1024, 1024, kernel_size=3, padding=1),
nn.LeakyReLU(negative_slope=0.1)
]
layers += [
nn.Flatten(),
nn.Linear(S * S * 1024, 4096), # Linear 1
nn.Dropout(),
nn.LeakyReLU(negative_slope=0.1),
nn.Linear(4096, S * S * self.depth), # Linear 2
]
self.model = nn.Sequential(*layers)
def forward(self, x):
return torch.reshape(
self.model.forward(x),
(x.size(dim=0), S, S, self.depth)
)Để in ra kiến trúc của mô hình kèm đầu ra và đầu vào, bạn có thể sử dụng thư viện torch-summary để hiển thị.
Với đoạn code hiển thị như sau:
from torchsummary import summary
model = YOLOv1()
summary(model, (3, 448, 448))Kết quả in ra:
 Bạn có thể học lập trình và kiểm tra kích cỡ các lớp song song với nhau để đảm bảo bạn đang thực hiện chính xác.
Bạn có thể học lập trình và kiểm tra kích cỡ các lớp song song với nhau để đảm bảo bạn đang thực hiện chính xác.
Vậy là team đã trình bày xong được kiến trúc của mô hình YOLO. Trong bài tiếp theo chúng tôi sẽ giải thích chi tiết hàm mất mát của mô hình này.
Bạn cùng theo dõi nhé.
Phần 2 - Giải thích đầu ra và đầu vào của mô hình YOLO
Chúng ta sẽ đi cùng chuỗi bài viết tiền xử lý dữ liệu cho mô hình YOLO - nhận diện vật thể trong hình ảnh.
Các khái niệm được đề cập trong bài
Box dự đoán (Predicted Box)
Chỉ số IOU
1) Đầu vào của YOLO
Như chúng ta đã tìm hiểu trong bài trước, Thuật toán YOLO sẽ chia bức ảnh thành một lưới có kích cỡ S x S cụ thể là cỡ 7x7 như hình dưới đây:
 Với mỗi ô trong lưới 7x7 này, mô hình YOLO sẽ vẽ các box dự đoán với mục tiêu là xấp xỉ được grounding true box chính là box nhãn (màu đỏ) của chúng ta.
Với mỗi ô trong lưới 7x7 này, mô hình YOLO sẽ vẽ các box dự đoán với mục tiêu là xấp xỉ được grounding true box chính là box nhãn (màu đỏ) của chúng ta.

Trong trường hợp này Box dự đoán chính là hình chữ nhật màu trắng với tâm nằm trong ô màu trắng. Vậy thì giả sử nếu mỗi một ô này YOLO sẽ học 2 box dự đoán thì với 7 x 7 ô thì chúng ta sẽ có bao nhiêu box dự đoán?
Câu trả lời là 7 x 7 x 2 = 98 box dự đoán
Box dự đoán

Chi tiết thông tin lưu trữ của một box dự đoán được bố trí như sau: 5 giá trị bao gồm x, y, w, h, confidence. Những giá trị này mang tính chất tỉ lệ, không phải tính chất tuyệt đối.
(x, y) là tọa độ tâm của box dự đoán tỉ lệ với chiều của ô mà tâm đó nằm bên trong. Ví dụ có 7x7 ô thì một ô sẽ có chiều 64x64 ( Cách tính: 448 / 7 = 64)
Cách tính hai biến này sẽ được trình bày trong phần tiếp theo
width chiều dài của box dự đoán tỉ lệ với chiều dài của ảnh
Khi lập trình bạn có thể code như sau:
(xmax - xmin) / image_width
height chiều cao của box dự đoán tỉ lệ với chiều cao của ảnh
Khi lập trình bạn có thể code như sau:
(ymax - ymin) / image_height
Giá trị confidence thể hiện giá trị IOU giữa box dự đoán với box grounding true. IOU là giá trị thể hiện sự giao thoa giữa hai box bất kỳ. Nếu hai box giao thoa càng nhiều thì giá trị này càng lớn.

2) Đầu ra của YOLO
Một cách ngắn gọn đầu ra YOLO sẽ là một tensor có chiều: S × S × (B x 5 + C)
Trong trường hợp này:
S = 7, chiều của lưới tạo ra 7 x 7 = 47 ô
B là số lượng bounding box dự đoán ở mỗi ô của grid. Trường hợp này B = 2
C là kết quả tự tin dự đoán là ô này dự đoán nhãn nào. Bài toán 20 nhãn thì C = 20
Vây là YOLO sẽ trả về 7 x 7 vector, mỗi vector đại diện cho một cell bao gồm B x 5 + C = 2 x 5 + 20 = 30 phần tử
20 phần tử đầu đầu tiên đại diện cho vector dự đoán trên 20 nhãn. Tổng các giá trị tạo nên biến cố đầy đủ hay có tổng bằng 1.
5 phần tử tiếp theo (hiển thị bằng màu hồng) đại diện cho 5 thông số x, y, w, h, confidence của box dự đoán 1
5 phần tử tiếp theo (hiển thị bằng màu xanh) đại diện cho 5 thông số x, y, w, h, confidence của box dự đoán 2
Trên ảnh bạn có thể hình dung chi tiết về đầu ra của mô hình YOLO.
Trong bài toán tiếp theo, đội ngũ ProtonX sẽ hướng dẫn các bạn chuẩn bị dữ liệu để tiến hành xử lý dữ liệu và training mô hình nhé.
Phần 3 - Cùng phân tích kỹ các chỉ số của Box dự đoán
Trong Phần 2 - Giải thích đầu ra và đầu vào của mô hình YOLO , khái niệm Box dự đoán đã được đề cập dùng để khoanh vuông đối tượng chúng ta cần nhận diện.
1) Nhắc lại một số khái niệm trong phần trước
Trong bài này chúng ta cùng đào sâu 5 chỉ số mã YOLO cần học cho mỗi box này.
Như chúng ta đã biết, một bounding box nhãn có hai điểm min và max. Vậy từ hai giá trị này làm thế nào để chúng ta bố trí dữ liệu để đào tạo bao gồm 5 giá trị x, y, w, h, confidence đã được đề cập trong phần 2.
2) Ô chứa tâm của box dự đoán
Trong bài trước chúng ta đã nhắc đến YOLO sẽ chia ảnh thành S x S ô, mỗi một ô này sẽ dự đoán ra B box dự đoán, trường hợp này đang đặt B = 2. Tâm của hai box này sẽ nằm trong ô. Cho nên khi tiến hành dự đoán YOLO sẽ phải xác định vị trí của tâm tỉ lệ với chiều của ô này, trường hợp này là 64.

3) Các chỉ số của box dự đoán
3.1) Chỉ số chiều dài (w), chiều cao (h)

Với hai giá trị min và max ta có thể tính ra được:
Chiều dài của box dự đoán
box_width = xmax - xmin
Giá trị w là tỉ lệ giữa chiều dài của box và chiều dài của ảnh
w = box_width / image_width
3.2) Chỉ số tâm của box (x, y)

Tọa độ tâm của bounding box theo chiều của ảnh
x_center = (xmax + xmin) / 2
y_center = (ymax + ymin) / 2
Chiều một ô trường hợp này
cell_size = 64
Dòng hiện tại của ô
row = y_center // cell_size
col = x_center // cell_size
Trong trường hợp này ô chứa tâm nằm ở dòng có chỉ mục tính từ 0 là dòng số 5 và cột số 4. Nhiệm vụ tính dòng và cột là để tỉm ra:
Khoảng cách từ tâm bounxing box tới viền của ô hiện tại (màu xanh)
a = x_center - col x cell_size
b = y_center - row x cell_size
Tỉ lệ của khoảng cách này trên chiều của ô
x = a / cell_size
y = b / cell_size
Đây chính là cặp x, y mà YOLO sẽ cố gắng học
3.3) Chỉ số tự tin - confidence
Với nhãn thì chỉ số này sẽ bằng 1 vì nhãn chính là grounding true box
Với dự đoán của YOLO thì chỉ số này được đo lượng bằng giá trị IOU, độ đo thể hiện sự khớp giữa box dự đoán và grounding true box. IOU là giá trị thể hiện sự giao thoa giữa hai box bất kỳ. Nếu hai box giao thoa càng nhiều thì giá trị này càng lớn.
Để tính IOU ta cần tính diện tích phần giao và diện tích phần hợp, sau đó tính tỉ lệ giữa hai phần này.
3.1.1) Cách tính diện tích phần giao:
Để tính diện tích phần giao, ta cần đi tìm hai tọa độ của hình chữ nhật phần giao:
Tọa độ bên trái nằm trên: (i_min_x, i_min_y)
Tọa độ bên phải nằm dưới: (i_max_x, i_max_y)

Cách tìm ra tọa độ trái bên trên:
Chú ý rằng có khả năng box A nằm trước box B hoặc ngược lại cho nên ta cần thiết kế theo cách tổng hợp như sau:

Tọa độ bên trái nằm trên: (i_min_x, i_min_y)
i_min_x = max(a_min_x, b_min_x)
i_min_y = max(a_min_y, b_min_y)
Tương tự ta có thể tọa độ bên phải nằm dưới: (i_max_x, i_max_y)
i_max_x = min(a_max_x, b_max_x)
i_max_y = min(a_max_y, b_max_y)
Sau khi biết hai tọa độ này bạn có thể tính ra chiều dài và chiều cao của phần giao:

Chiều dài của phần giao
intersection_width = i_max_x - i_min_x
Chiều cao của phần giao
intersection_height = i_max_y - i_min_y
Diện tích của phần giao
I = intersection_width x intersection_height
Chú ý: Diện tích này có thể âm trong trường hợp hai box không đè lên nhau nên cần so sánh với 0 khi lập trình.
3.1.2) Cách tính diện tích phần hợp:
Diện tích phần hợp bằng tổng diện tích của A và B trừ đi diện tích phần giao:
U = A + B - I
3.1.3) Cách lập trình IOU như sau:
def calculate_iou(A, B):
x1_inter = max(A[0], B[0])
y1_inter = max(A[1], B[1])
x2_inter = min(A[2], B[2])
y2_inter = min(A[3], B[3])
# Tính diện tích phần giao
intersection = max(0, x2_inter - x1_inter) * max(0, y2_inter - y1_inter)
# Tính diện tích của A và B
area_A = (A[2] - A[0]) * (A[3] - A[1])
area_B = (B[2] - B[0]) * (B[3] - B[1])
# Tính diện tích phần hợp
union = area_A + area_B - intersection
# Tính IOU
iou = intersection / union if union > 0 else 0
return iou
Giá trị này chính là chỉ số thứ 5 mà YOLO cần dự đoán được.
Vậy là bạn đã cùng tìm hiểu chi tiết các giá trị nằm trong box dự đoán đầu ra của YOLO.
Trong những bài tiếp theo chúng ta sẽ đi sâu và kiến trúc mô hình YOLO nhé.
Phần 1 - Xử lý bộ dữ liệu cho mô hình phát hiện đối tượng (Object Detection)
Mô hình YOLO là một mô hình rất phổ biến trong nhận diện hình ảnh vì tính tiện dụng của mình.
Phiên bản đầu tiên của mô hình này chủ yếu sử dụng kiến trúc CNN. Kiến trúc CNN được đề cập chi tiết tại đây.
Để có thể chuẩn bị dữ liệu cho mình này, bạn cần nắm được đầu ra của mô hình và lập trình sao cho với các bộ dữ liệu khác nhau, bạn có thể cung cấp cấu trúc mà YOLO yêu cầu.
Dưới đây là một ví dụ tiền xử lý nhãn cho bộ dữ liệu Pascal VOC
1) Giới thiệu bộ dữ liệu Pascal VOC
Pascal VOC là một bộ dữ liệu nổi tiếng cung cấp cho chúng ta dữ liệu phục vụ cho việc nhận diện đối tượng trong ảnh. Trong bài này chúng ta sẽ sử dụng dữ liệu từ năm 2017 để thực hành.
Một cặp dữ liệu của VOC bao gồm 2 phần
Hình ảnh dưới dạng Tensor
Nhãn của ảnh này dưới dạng như sau

{
"annotation": {
"folder": "VOC2007",
"filename": "000219.jpg",
"source": {
"database": "The VOC2007 Database",
"annotation": "PASCAL VOC2007",
"image": "flickr",
"flickrid": "321854556",
},
"owner": {"flickrid": "momimdr", "name": "?"},
"size": {"width": "333", "height": "500", "depth": "3"},
"segmented": "0",
"object": [
{
"name": "motorbike",
"pose": "Left",
"truncated": "0",
"difficult": "0",
"bndbox": {"xmin": "120", "ymin": "333", "xmax": "310", "ymax": "464"},
}
],
}
}Object chính là phần bounding box của bức ảnh mà chúng ta cần.
{
"object": [
{
"name": "motorbike",
"pose": "Left",
"truncated": "0",
"difficult": "0",
"bndbox": {"xmin": "120", "ymin": "333", "xmax": "310", "ymax": "464"},
}
],
}Object này chính là chứa khung đỏ bao quanh (bounding box) chiếc xe máy mà chúng ta nhìn thấy ảnh bên trên. Cùng phân tích xem các giá trị xmin, ymin, xmax, ymax thể hiện ý nghĩa như thế nào của khung?
2) Scale ảnh về kích cỡ 448 x 448
 Ảnh sẽ được resize ở kích thước bất kỳ về một Tensor có cỡ 3 x 448 x 448 với
Ảnh sẽ được resize ở kích thước bất kỳ về một Tensor có cỡ 3 x 448 x 448 với
3 lớp đại diện cho 3 màu đỏ, xanh lục, xanh dương
448 là chiều dài
448 là chiều cào
Cách load dữ liệu và resize ngay sau đó rất đơn giản, bạn có thể load trực tiếp từ thư viện Pytorch
dataset = VOCDetection(
root='data',
year='2007',
image_set=('train' if set_type == 'train' else 'val'),
download=True,
transform=T.Compose([
T.ToTensor(),
T.Resize((448, 448)
)
])
)Hàm resize về cỡ 448 x 448 đã nằm ngay trong phần load dữ liệu này.
3) Bounding box là gì
Bounding box là hình chữ nhật bao quanh vật thể được xác lập bởi 2 điểm.
Điểm min: Điểm nằm bên trái góc trên của bounding box
Điểm max: Điểm nằm bên phải góc dưới của bounding box
 Trong trường hợp này bạn cần chú ý:
Trong trường hợp này bạn cần chú ý:
Trục x nằm ngang bên trên
Trục y nằm dọc bên tay trái
Điểm min có giá trị theo trục x là xmin = 161 và theo trục y là ymin = 298
Điểm max có giá trị theo trục x là xmax = 417 và theo trục y là ymax = 415.
4) Giãn Bounding Box

Tuy nhiên khi thay đổi kích cỡ của ảnh thì cũng cần thay đổi kích cỡ của bouding box vì thế trong trong trường hợp này ta sẽ scale cả bouding box tương ứng.
def get_bounding_boxes(label):
width, height = get_dimensions(label)
x_scale = config.IMAGE_SIZE[0] / width
y_scale = config.IMAGE_SIZE[1] / height
boxes = []
objects = label['annotation']['object']
for obj in objects:
box = obj['bndbox']
coords = (
int(int(box['xmin']) * x_scale),
int(int(box['xmax']) * x_scale),
int(int(box['ymin']) * y_scale),
int(int(box['ymax']) * y_scale)
)
name = obj['name']
boxes.append((name, coords))
return boxesNhìn hàm trên bạn có thể thấy ta sẽ:
Tìm độ giãn x_scale theo chiều dài của ảnh mới (448) và chiều dài của ảnh cũ
Tìm độ giản y_scale theo chiều cao của ảnh mới (448) và chiều cao của ảnh cũ
Sau khi có hai độ giãn này
Giãn các giá trị xmin, xmax theo độ giãn x_scale
Giãn các giá trị ymin, ymax theo độ giãn y_scale
5) Chia ảnh thành Grid
Thuật toán YOLO sẽ chia ảnh thành một Grid cỡ S x S và nếu trong trường hợp này S = 7 thì Grid sẽ trông như thế này:
Tức là ta sẽ có 7x7 = 49 ô.
Từ mỗi ô này, YOLO sẽ cố gắng vẽ ra được các bounding box khớp nhất với bounding box màu đỏ nhãn. Ô này sẽ chứa tâm của bounding box Yolo học.
 Chi tiết Đầu ra của Yolo sẽ được mô phỏng dưới hình dạng này:
Chi tiết Đầu ra của Yolo sẽ được mô phỏng dưới hình dạng này:
 Chi tiết sẽ được giải thích tại phần hai sẽ được công bố vào ngày mai 07/11/2023. Bạn cũng chờ đón nhé.
Chi tiết sẽ được giải thích tại phần hai sẽ được công bố vào ngày mai 07/11/2023. Bạn cũng chờ đón nhé.