Học gì để trở thành lập trình viên Tensorflow?

Mặc dù gần đây có sự cạnh tranh nảy lửa giữa Pytorch và Tensorflow - hai framework để xây dựng mô hình AI, tuy nhiên thì theo đánh giá của team ProtonX thì Tensorflow vẫn là lựa chọn tốt hơn khi triển khai mô hình AI trên sản phẩm thực tế khi Tensorflow được Google đứng sau hỗ trợ phát triển trên nhiều nền tảng như Web, Android, các thiết bị phần cứng chuyên biệt.
Ví dụ bạn có thể xây dựng mô hình AI chạy trên trình duyệt như sau rất nhanh:
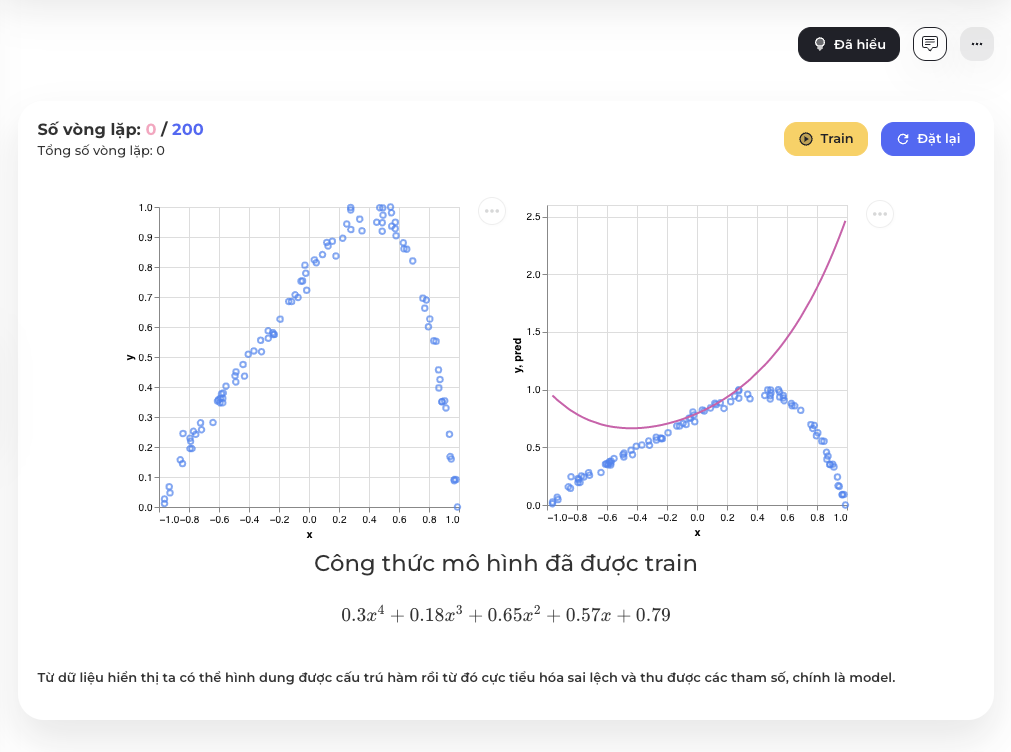
Vậy để trở thành một lập trình viên Tensorflow thì bạn cần nắm chắc những kiến thức gì? Sau đây là một số từ khóa quan trọng mà bạn cần biết:
1) Ngôn ngữ lập trình Python: Để sử dụng TensorFlow hiệu quả, bạn phải hiểu rõ về ngôn ngữ lập trình Python, bao gồm cú pháp cơ bản, cấu trúc dữ liệu và lập trình hướng đối tượng. Học Python miễn phí tại đây
2) Đại số tuyến tính & Giải tích: TensorFlow phụ thuộc rất nhiều vào đại số tuyến tính và giải tích, vốn là nền tảng toán học cho mạng nơ-ron và học sâu. Việc nắm các khái niệm như ma trận, vectơ, đạo hàm riêng, gradient và thuật toán tối ưu hóa là rất quan trọng.
3) Mạng nơ-ron & khái niệm học sâu: Cần hiểu sâu về mạng nơ-ron và khái niệm học sâu để sử dụng TensorFlow một cách hiệu quả. Bạn nên hiểu kiến trúc của mạng nơ-ron, hàm phi tuyến, lan truyền ngược và thuật toán tối ưu hóa. Chi tiết các công nghệ được chia sẻ miễn phí tại đây.
4) API TensorFlow: API cho phép ta sử dụng lại những hàm có sẵn thay vì phải tự lập trình, TensorFlow là thư viện phần mềm mã nguồn mở và họ cung cấp cho chúng ta rất nhiều hàm tính toán có thể sử dụng lại.
Để trở thành nhà phát triển TensorFlow, bạn phải làm việc thuần thục với các API này, đặc biệt là cách sử dụng TensorFlow để xây dựng, đào tạo và đánh giá mạng nơ-ron.
5) Học máy: TensorFlow thường được sử dụng để xây dựng mô hình học máy, vì vậy điều quan trọng là phải hiểu rõ về các kỹ thuật học máy khác nhau, bao gồm học có giám sát, học không giám sát và học tăng cường. Xem thêm các cách phân loại học máy tại đây.
Bạn cũng nên hiểu các kỹ thuật đánh giá mô hình, chẳng hạn như độ chính xác (precision), recall và điểm F1.
6) Đào tạo, đánh giá và tối ưu hóa mô hình: Hầu hết thời gian chúng ta sẽ xoay quanh các khái niệm đào tạo, đánh giá và tối ưu hóa các mô hình mạng nơ ron. Điều này bao gồm hiểu biết về overfitting và cách khắc phục, cũng như cách sử dụng các kỹ thuật như dừng sớm cải thiện hiệu suất của mô hình. Học thử cách training và đánh giá mô hình tại đây.
7) TensorFlow dành cho thị giác máy tính và xử lý ngôn ngữ tự nhiên: TensorFlow có các thư viện chuyên biệt dành cho thị giác máy tính và xử lý ngôn ngữ tự nhiên, chẳng hạn như API nhận diện đối tượng (Object Detection) của TensorFlow. Hiểu các thư viện này và cách sử dụng chúng một cách hiệu quả là một phần quan trọng để trở thành nhà phát triển TensorFlow.
Ngoài ra nếu bạn muốn có một chứng chỉ từ Google về khả năng lập trình Tensorflow của mình, bạn có thể tham khảo lớp học Luyện thi chứng chỉ Tensorflow
Hi vọng những đầu mục trên đây sẽ giúp bạn có một lộ trình học Tensorflow hiệu quả trong năm 2023.
Sử dụng Stable Diffusion để sinh ảnh cho Tết cuối năm
Vậy là hôm nay chúng ta bắt đầu tiễn ông Công ông Táo và sắp đón một cái Tết năm 2023 với nhiều hi vọng hơn nữa.
Hôm nay ProtonX team sẽ hướng dẫn bạn sử dụng mô hình Stable Diffusion để sinh ảnh cho ngày Tết.
Bạn có thể sử dụng ảnh này làm lì xì, ốp điện thoại để tặng bạn gái cũng được. :D
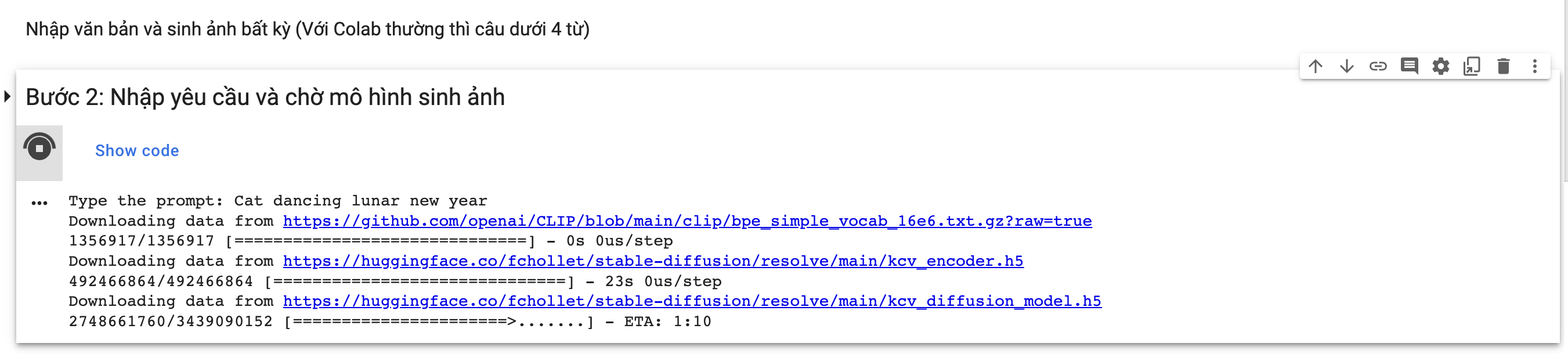
Đây là kết quả khi bạn nhập cụm từ
Cat lunar new year
để sinh ảnh con Mèo cho tết Âm:

Model sẽ giúp bạn sinh ảnh Mèo cho Tết.
Hướng dẫn sử dụng
Bước 0: Bạn truy cập vào Notebook ở đây.
Bước 1: Bạn nhấn vào cài đặt thư viện cần thiết

Bước 2: Nhập miêu tả ảnh bạn muốn, nhấn Enter và chờ mô hình sinh ảnh.
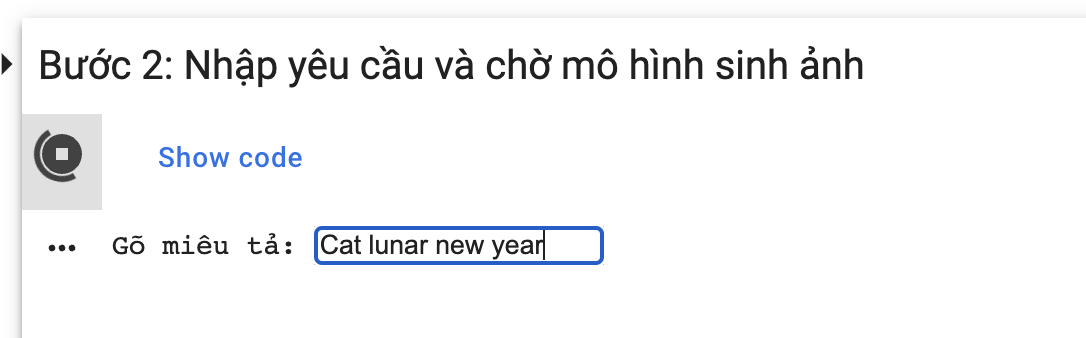
Lúc đầu tiên sẽ phải download bộ tham số nên sẽ hơi lâu một chút, trong những lần nhập tiếp theo sẽ nhanh hơn.
Kết quả thu được:
Ví dụ bạn nhập
Hello Kitty
Kết quả thu được:

Convert bộ dữ liệu Coco thành TF Records để tăng tốc quá trình xử lý dữ liệu
1) Giới thiệu về TFRecord
Tensorflow là framework được thiết kế phù hợp với môi trường Production vì framework này có rất nhiều công cụ làm việc với dữ liệu lớn (Big Data).
Một trong những công cụ chúng ta rất cần thiết đó là TF Record giúp cải thiện tốc độ load dữ liệu và xử lý.
Định dạng TFRecord là dạng lưu trữ nhị phân của Tensorflow. Một số lợi điểm khi sử dụng kiểu lưu trữ này:
- Tương tự như Apache Parquet, sử dụng TFRecord giúp tiết kiệm không gian lưu trữ.
- Tốc độc đọc/ghi cao khi TF hỗ trợ đọc/ghi song song.
2) Khám phá bộ dữ liệu COCO
Bộ dữ liệu COCO có thể sử dụng cho bài toán nhận diện hình ảnh. Bộ dữ liệu bao gồm hai phần:
- Phần 1) Ảnh được lưu dưới dạng JPG
Một ảnh trong bộ dữ liệu này.

- Phần 2 ) Thông tin meta-data lưu dưới dạng JSON file bao gồm
- id: mã metadata - dạng int
- image_id: mã ảnh - dạng int
- category_id: nhãn - dạng int
- segmentation: đường bao quanh đối tượng - mảng các giá trị float
- bbox: tọa độ các đỉnh hình vuông bao quanh đối tượng - mảng các giá trị float
- area: diện tích của bounding box - mảng các giá trị float
Ví dụ
{ "id": 1410165, "category_id": 1, "iscrowd": 0, "segmentation": [ [ 486.34, 239.01, 495.95, ... 244.39 ] ], "image_id": 245915, "area": 1775.8932499999994, "bbox": [ 86.0, 65.0, 220.0, 334.0 ]
3) Hướng dẫn convert bộ dữ liệu COCO sang TFRecord
3.1) Hướng dẫn convert bộ dữ liệu COCO sang TFRecord
Tiến hành download ảnh:
root_dir = "datasets" images_dir = os.path.join(root_dir, "val2017") annotations_dir = os.path.join(root_dir, "annotations") annotation_file = os.path.join(annotations_dir, "instances_val2017.json") images_url = "http://images.cocodataset.org/zips/val2017.zip" annotations_url = ( "http://images.cocodataset.org/annotations/annotations_trainval2017.zip" ) # Tải ảnh if not os.path.exists(images_dir): image_zip = tf.keras.utils.get_file( "images.zip", cache_dir=os.path.abspath("."), origin=images_url, extract=True, ) os.remove(image_zip)
Tiến hành download meta-data:
# Tải meta data if not os.path.exists(annotations_dir): annotation_zip = tf.keras.utils.get_file( "captions.zip", cache_dir=os.path.abspath("."), origin=annotations_url, extract=True, ) os.remove(annotation_zip) print("The COCO dataset has been downloaded and extracted successfully.")
Kiểm tra số lượng mẫu:
import json with open(annotation_file, "r") as f: annotations = json.load(f)["annotations"] print(f"Number of images: {len(annotations)}")
Chúng ta có 36781 mẫu
Number of images: 36781
Ước tính số lượng file Tfrecord bằng việc tính toán như sau: nếu bạn muốn một file TFRecord chứa 4096 ảnh thì:
+ 1 khi số lượng ảnh không chia hết cho số lượng file.
Ở đây mình sẽ có file.
Code tính số file:
tfrecords_dir = "coco-tfrecords" num_samples = 4096 num_tfrecods = len(annotations) // num_samples if len(annotations) % num_samples: num_tfrecods += 1 # add one record if there are any remaining samples if not os.path.exists(tfrecords_dir): os.makedirs(tfrecords_dir) # creating TFRecords output folder
3.2) Hướng dẫn convert bộ dữ liệu COCO sang TFRecord
Với các dạng dữ liệu khác nhau ta sẽ sử dụng các cách convert khác nhau:
- Ảnh ta sẽ chuyển thành dạng nhị phân với hàm sau
def image_feature(value): """Returns a bytes_list from a string / byte.""" return tf.train.Feature( bytes_list=tf.train.BytesList(value=[tf.io.encode_jpeg(value).numpy()]) )
- Số nguyên, số thực hay mảng số thực được chuyển như sau:
def float_feature(value): """Returns a float_list from a float / double.""" return tf.train.Feature(float_list=tf.train.FloatList(value=[value])) def int64_feature(value): """Returns an int64_list from a bool / enum / int / uint.""" return tf.train.Feature(int64_list=tf.train.Int64List(value=[value])) def float_feature_list(value): """Returns a list of float_list from a float / double.""" return tf.train.Feature(float_list=tf.train.FloatList(value=value))
Sau đó bạn kết hợp tất cả các cách chuyển này vào trong một hàm thực hiện trên một mẫu, lưu ý một mẫu sẽ được lưu bằng hàm tf.train.Example
def create_example(image, path, example): feature = { "image": image_feature(image), "path": bytes_feature(path), "area": float_feature(example["area"]), # Số thực thì bạn dùng float_feature "bbox": float_feature_list(example["bbox"]), # Mảng số thực thì bạn dùng float_feature_list "category_id": int64_feature(example["category_id"]), # Số nguyên thì dùng int64_feature "id": int64_feature(example["id"]), "image_id": int64_feature(example["image_id"]), } return tf.train.Example(features=tf.train.Features(feature=feature))
Bước cuối cùng ta sẽ lặp qua tất cả ảnh và build ra từng file TF Record một:
for tfrec_num in range(num_tfrecods): # Cắt mẫu để chia ra file tương ứng samples = annotations[(tfrec_num * num_samples) : ((tfrec_num + 1) * num_samples)] # Tiến hành ghi ra file này with tf.io.TFRecordWriter( tfrecords_dir + "/file_%.2i-%i.tfrec" % (tfrec_num, len(samples)) ) as writer: # Đọc từng ảnh và ghi vào file for sample in samples: image_path = f"{images_dir}/{sample['image_id']:012d}.jpg" with open(image_path, "rb") as local_file: raw = local_file.read() image = tf.image.decode_jpeg(raw) example = create_example(image, image_path, sample) writer.write(example.SerializeToString())
Sau khi thực hiện xong kết quả sẽ thu được như sau:
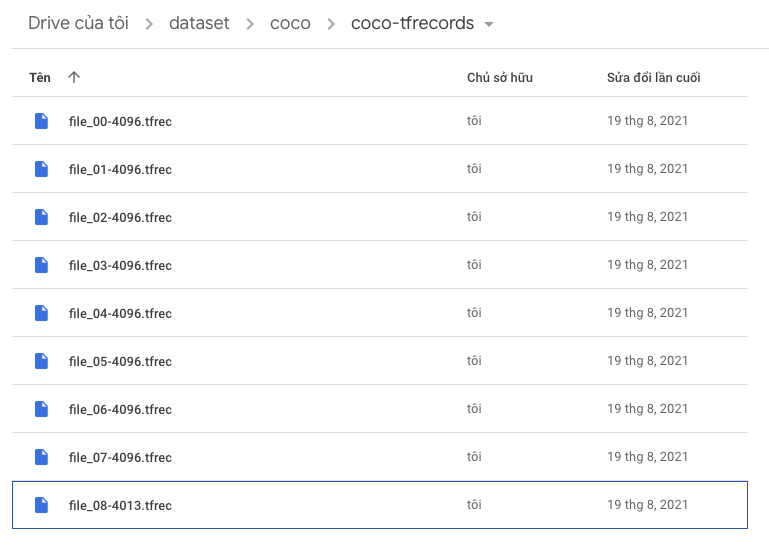
Trong bài tiếp theo mình sẽ hướng dẫn bạn cách để đọc các file TFRecords đã được lưu.
Hi vọng bạn đã có thêm một lựa chọn tốt nữa để xây dựng được một hệ thống AI có khả năng nhân rộng cao.