Tăng tốc truy vấn dữ liệu với Apache Parquet
Apache Parquet là một định dạng file hỗ trợ việc xử lý data phức tạp với rất nhiều những đặc tính thú vị.
Trong một số trường hợp bạn có thể sử dụng định dạng Parquet thay vì sử dụng file CSV vì 2 lý do sau:
- Khi bạn cần lưu trữ tiết kiệm
- Bạn cần truy vấn nhanh theo cột trong bài toán cụ thể của mình
1) Hướng cột - Columnar
Không như những dạng hướng theo dòng như CSV, Parquet là dạng dữ liệu hướng theo cột, tức là các cột sẽ được lưu trữ liền kề nhau thay vì các dòng.
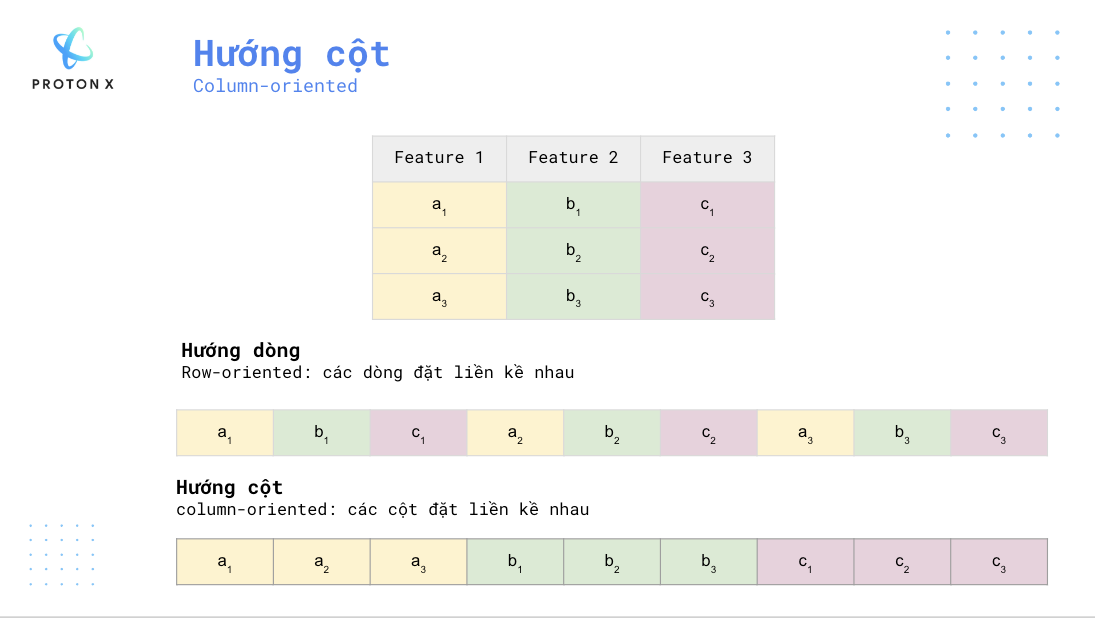
2) Lưu trữ hướng cột
Khi ổ đĩa quay, dữ liệu ghi trên đĩa sẽ được đọc bởi đầu đọc. Mỗi giá trị x ở dưới được biểu diễn bởi một cột của bảng.

Giả sử bạn chỉ muốn đọc cột Feature 3 thì với dữ liệu hướng dòng (row-oriented) bạn cần đọc tất cả các dòng, ở mỗi dòng bạn lại thu được một giá trị ở cột Feature 3.
Giả sử bạn có một bảng có dòng và 3 cột thì bạn cần duyệt qua toàn bộ số dòng này mới lấy được cột Feature 3.
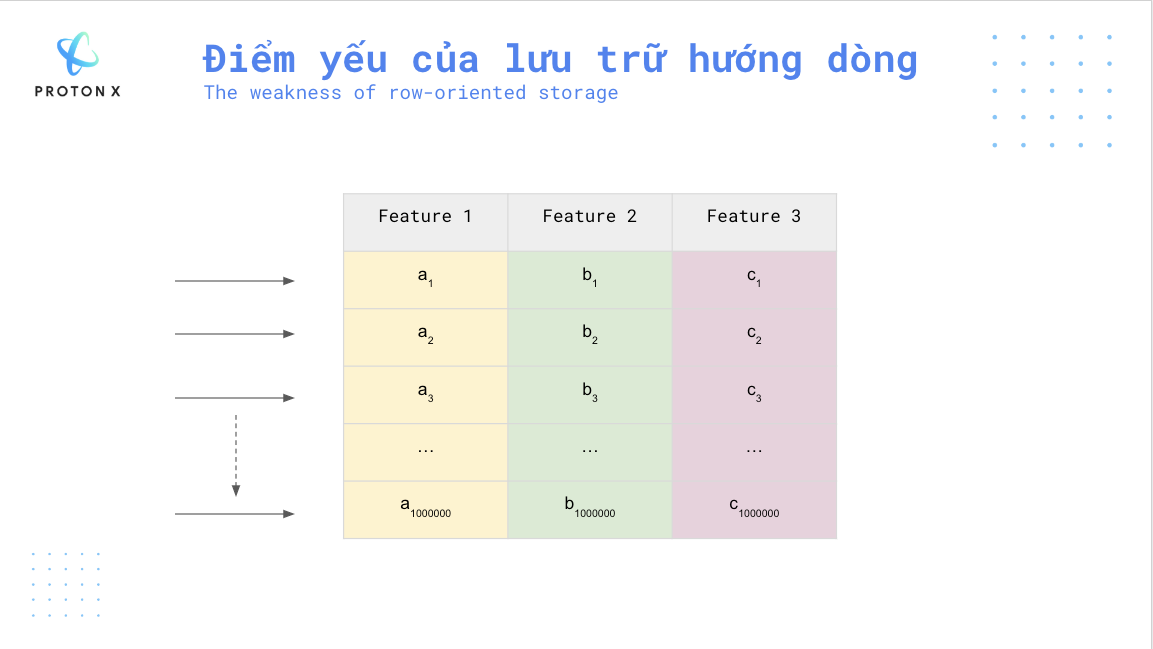
Trong trường hợp, nếu ta sử dụng lưu trữ hướng cột sẽ cho tốc độ nhanh hơn nhiều.
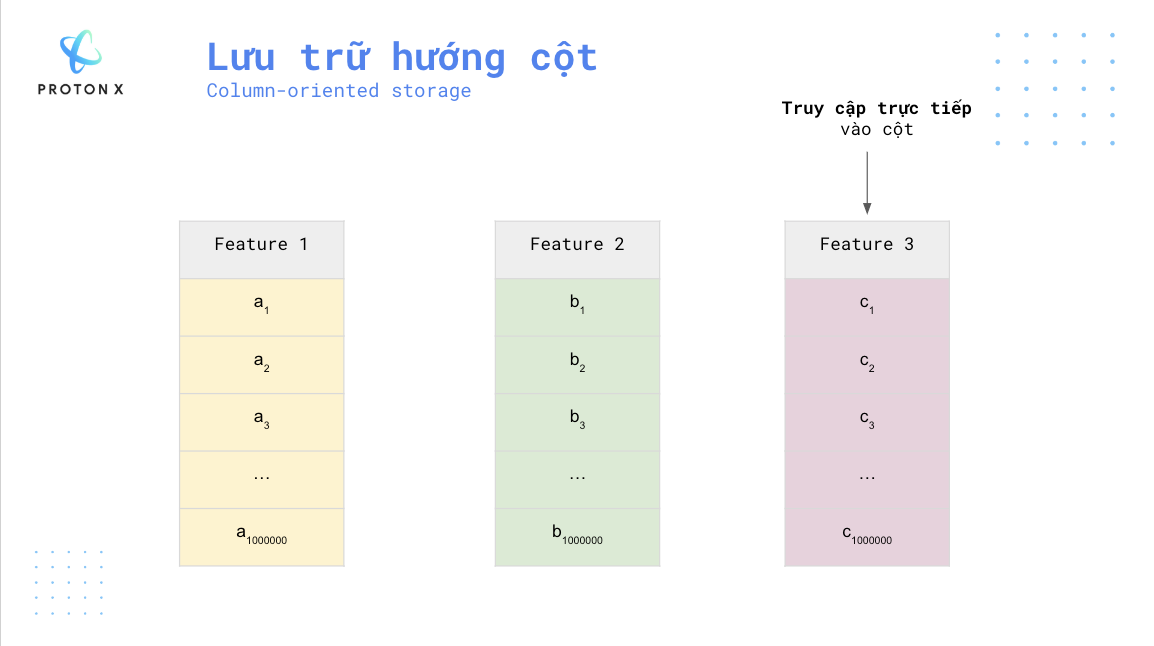
Ngoài ra lưu trữ hướng cột cũng cho ta một số lợi thế về lưu trữ khi các giá trị trong cột có xu hướng giống nhau nên ta có thể sử dụng các thuật toán nén. Vì thế file Parquet sẽ nhẹ hơn các dạng lưu trữ khác. Ví dụ một file CSV 1TB khi chuyển sang dạng Parquet chỉ khoảng 100GB (còn 10% không gian lưu trữ).
3) Thực hiện tạo Parquet file với Pyarrow
Cài đặt thư viện:
!pip install pyarrow
Tạo mảng chứa 100 phần tử:
import numpy as np import pyarrow as pa arr = pa.array(np.arange(100)) print(f"{arr[0]} .. {arr[-1]}")
Định dạng Parquet là bảng chứa rất nhiều cột nên ta cần đặt tên cho cột này.
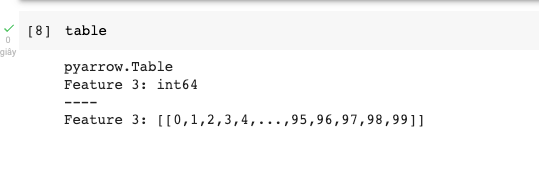
table = pa.Table.from_arrays([arr], names=["Feature 3"]) import pyarrow.parquet as pq pq.write_table(table, "example.parquet", compression=None)
Kết quả ta đã được một file này:
4) Tiến hành đọc file Parquet
import pyarrow.parquet as pq table = pq.read_table("example.parquet")
Kết quả hiện ra:
5) Kết luận
Hi vọng bạn đã có thêm lựa chọn khi xử lý dữ liệu lớn.