Phân biệt hai vị trí Kỹ sư dữ liệu (Data Engineer) và nhà khoa học dữ liệu (Data Scientist)
Vẫn còn rất nhiều hiểu nhầm về hai vị trí Kỹ sư dữ liệu (Data Engineer) và nhà khoa học dữ liệu (Data Scientist) nên trong bài hôm nay ProtonX team sẽ giúp bạn phân biện hai vị trí để bạn có thể lựa chọn đúng đắn cho công việc của mình nhé.
Để dễ dàng so sánh hai vị trí này với nhau thì đầu tiên có thể ta cần tập trung vào quy trình xử lý dữ liệu.
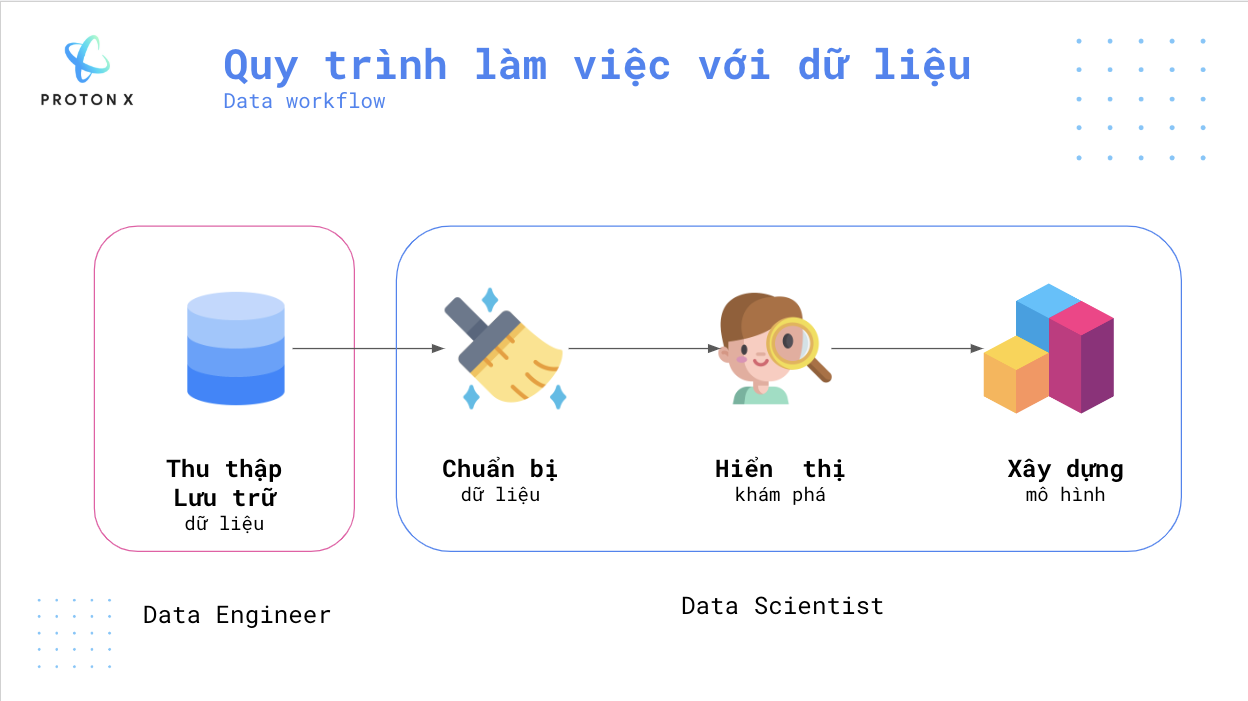
Một quy trình xử lý dữ liệu chuẩn sẽ có các thành phần: Thu thập/Lưu trữ dữ liệu, chuẩn bị dữ liệu, hiển thị/khám phá dữ liệu và xây dựng mô hình.
Một quy trình chuẩn thì người kỹ sư dữ liệu sẽ phụ trách phần đầu tiên tức là thu thập/lưu trữ dữ liệu còn nhà khoa học dữ liệu sẽ hoàn thiện 3 phần tiếp theo.
Chi tiết các bước sẽ được diễn giải dưới đây:
- Thu thập/Lưu trữ dữ liệu: Các kỹ sư dữ liệu sẽ tham gia vào việc tổ chức lưu trữ dữ liệu. Ví dụ khi xây dựng Studio., team có một bạn phụ trách thu thập (crawl) dữ liệu từ trên Internet, tiền xử lý đơn giản và tổ chức lưu trữ về cơ sở dữ liệu không quan hệ (NoSQL), cụ thể database team sử dụng đó là MongoDB. Nếu bạn yêu thích công việc này có thể tìm hiểu: Học gì để trở thành kỹ sư dữ liệu?
Rõ ràng công việc này yêu cầu bạn cần hiểu về cơ sở dữ liệu, biết cách lưu trữ và truy vấn.
- Chuẩn bị dữ liệu: Bước này tùy theo các dự án, cả người kỹ sư dữ liệu và nhà khoa học dữ liệu đều có thể tham gia quy trình này.
Ví dụ đơn giản về các trang web thu thập từ trên mạng về có rất nhiều phần thông tin quảng cáo, ảnh hưởng đến chất lượng mô hình vì vậy khi chuẩn bị dữ liệu, người xử lý cần phải viết rất nhiều những đoạn mã để xử lý, xóa hoặc thậm chí làm mặt nạ (masking).
Ví dụ:
Câu đầu vào:
Địa điểm: Hoàng Mai, Hà Nội
Sau khi xử lý thêm mặt nạ: Câu đầu ra:
Địa điểm: [Nhập địa chỉ của bạn]
- Hiển thị khám phá
Khâu này rất quan trọng, nhà khoa học dữ liệu sẽ hiển thị dữ liệu, giảm chiều dữ liệu đễ lựa chọn mô hình. Ví dụ phân phối dữ liệu đơn giản ta có thể lựa chọn những mô hình nhẹ như Hồi quy tuyến tính.
Các thuật toán quen thuộc để giảm chiều ví dụ như SVD, hay PCA. Học thêm về các thuật toán này tại lớp học MLEs - Scale ML System
Tuy nhiên tùy theo dữ liệu mà ta có thể sử dụng được tối đa, ví dụ với dữ liệu dạng bảng thì dễ dàng áp dụng các cách hiển thị khác nhau nhưng với dữ liệu văn bản thì số lượng công cụ hiển thị sẽ ít hơn rất nhiều.
- Sau khi đã lựa chọn được mô hình, bước thứ 4 là xây dựng và đánh giá
Trong bước này, nhà khoa học dữ liệu sẽ cần kiểm thử rất nhiều lựa chọn khác nhau, theo dõi để có kết luận được mô hình cho hiệu năng tốt nhất. Không phải lúc nào dùng những công nghệ tiên tiến nhất cũng cho kết quả tốt nhất.
Thử học cách đánh giá bài toán và xây dựng mô hình mạng nơ ron.
Ngoài ra ở khâu này, còn rất quan trọng việc bạn đã từng có kinh nghiệm hiểu về dữ liệu. Nếu bạn đã từng làm việc với dữ liệu ngành này trong quá khứ, thời gian phát triển sẽ nhanh hơn rất nhiều. Ví dụ về kinh nghiệm làm việc với dữ liệu ít.
Trên đây là cách đơn giản nhất để phân biệt được hai vị trí này, hi vọng sẽ giúp bạn lựa chọn đúng nghề nghiệp của mình.
Câu hỏi yêu thích phỏng vấn thuật toán của các công ty công nghệ
Bài toán "Two sum" trên LeetCode là một bài toán thông dụng được các công ty công nghệ sử dụng trong vòng phỏng vấn của mình nhằm mục đích kiểm tra kiến thức cơ bản của người lập trình về xử lý mảng và bảng băm. Bài toán phát biểu:
Cho một mảng số nguyên nums và một số nguyên target, trả về chỉ mục của hai số sao cho tổng của chúng bằng giá trị target.
Đường dẫn đề bài: https://leetcode.com/problems/two-sum/
Đây là lời giải Python:
class Solution: def twoSum(self, nums: List[int], target: int) -> List[int]: # Tạo một từ điển trống d = {} # Lặp qua mảng for i, num in enumerate(nums): # Kiểm tra xem số bù của số hiện tại có trong từ điển không - tức là cộng vào số hiện tại có bằng target hay không if target - num in d: # Nếu có, trả về chỉ số của số bù và số hiện tại return [d[target - num], i] # Ngược lại, thêm số hiện tại và chỉ số của nó vào từ điển d[num] = i
Cách này sử dụng bảng băm (công nghệ đằng sau một từ điển trong Python) để lưu trữ các số trong mảng và chỉ mục của chúng. Cho mỗi số trong mảng, nó kiểm tra xem số bù của số đó (target - num) đã có trong bảng băm hay chưa.
-
Nếu có tức là là chúng ta đã tìm thấy một cặp số mà chúng có tổng bằng target, sau đó chúng ta trả về chỉ mục của những số đó.
-
Nếu không chúng ta thêm số hiện tại và chỉ mục của nó vào bảng băm và tiếp tục với số tiếp theo.
Trong trường hợp này, giải pháp sử dụng bảng băm để lưu trữ các số và chỉ mục, vì vậy độ phức tạp thời gian lấy giá trị khỏi từ điển là O(1) vì ta không cần sắp xếp hoặc duyệt qua toàn bộ các phần tử. Tổng độ phức tạp thời gian là O(n), với n là số phần tử trong mảng.
Xem thêm về độ phức tạp về thuật toán nếu bạn chưa hiểu các công thức BigO.
Luyện tập thêm Leetcode tại lớp học Leetcode 200 - Luyện thuật toán với chuyên gia
Học gì để trở thành kỹ sư dữ liệu?
Nếu bạn chưa biết, công việc tiền xử lý dữ liệu là một công việc rất quan trọng trước khi training một mô hình học máy.
Người kỹ sư dữ liệu (Data Engineer) là người thiết kế, xây dựng và duy trì cơ sở hạ tầng và hệ thống hỗ trợ các ứng dụng hướng dữ liệu (data-driven), thường sử dụng các cấu trúc dữ liệu và thuật toán khác nhau để tối ưu hiệu năng. Tương lai các ứng dụng học máy sử dụng dữ liệu lớn (Big Data) sẽ trở nên phổ biến hơn vì vậy vị trí kỹ sư dữ liệu sẽ được tìm kiếm nhiều hơn bao giờ hết.
Tìm hiểu thêm về học máy tại lớp học AI miễn phí.
Đầu tiên thì kỹ sư dữ liệu cần học lập trình tốt. Ngôn ngữ phổ biến để xử lý dữ liệu tại thời điểm hiện tại là Python. Đây là ngôn ngữ được dùng nhiều nhất để làm Machine Learning vì tính đơn giản gọn nhẹ của nó.
Mình đã đóng gói các kiến thức Python vào lớp học Python miễn phí tại đây
- a. Cài đặt Python và các thư viện cần thiết:
- b. Tính chất đặc điểm
Python là ngôn ngữ thông dịch có:
- Điểm mạnh:
- Dễ viết/ Dễ đọc
- Quy trình phát triển phần mềm nhanh vì dòng lệnh được thông dịch thành mã máy và thực thi ngay lập tức
- Có nhiều thư viện mạnh để tính toán cũng như làm Machine Learning như Numpy, Sympy, Scipy, Matplotlib, Pandas, TensorFlow, Keras, vv.
- Điểm yếu:
- Mang đầy đủ điểm yếu của các ngôn ngữ thông dịch như tốc độ chậm, tiềm tàng lỗi trong quá trình thông dịch, source code dễ dàng bị dịch ngược.
- Ngôn ngữ có tính linh hoạt cao nên thiếu tính chặt chẽ.
- Lập trình song song không dễ dàng
- Điểm mạnh:
- c. Các cấu trúc dữ liệu trên Python
-
Cấu trúc dữ liệu là cách tổ chức và lưu trữ dữ liệu trong máy tính để có thể truy cập và chỉnh sửa hiệu quả. Một số cấu trúc dữ liệu phổ biến bao gồm mảng, danh sách liên kết, ngăn xếp, hàng đợi, cây và đồ thị.
-
Khái niệm Biến:
-
Các kiểu dữ liệu trong Python:
- Integer, Float và Boolean
- Chuỗi - String
- List-Based Collection
- List
- Linked List
- Stack
- Queue
- Tuple
- Từ điển - Dictionary
- Set
- Graph
- Binary Tree
-
Cấu trúc dữ liệu nâng cao
-
-
- d. Vòng lặp
- e. Hàm
- f. Thuật toán
- Thuật toán sắp xếp
- Đệ quy
- Các thuật toán tìm đường
- DFS và bài toán biển đảo
- Dijkstra: thuật toán tìm đường đi ngắn nhất từ một điểm bất kỳ đến các điểm còn lại
- Bellman Ford
- Prim
- Backtracking
- Linear + Binary Search
- Quy hoạch động - Floyd Warshall
Ngoài cấu trúc dữ liệu và giải thuật, người kỹ sư dữ liệu còn phải học rất nhiều chủ đề khác nhau bao gồm:
-
Lưu trữ và quản lý dữ liệu: Các kỹ sư dữ liệu nên có hiểu biết tốt về các loại hệ thống lưu trữ dữ liệu khác nhau, chẳng hạn như cơ sở dữ liệu quan hệ (SQL) và cơ sở dữ liệu không quan hệ (NoSQL), và có thể thiết kế và triển khai các giải pháp lưu trữ dữ liệu hiệu quả.
-
Xử lý và phân tích dữ liệu: Các kỹ sư dữ liệu nên nắm bắt được các kỹ thuật xử lý và phân tích dữ liệu, chẳng hạn như batch processing và stream processing, và có thể thiết kế và triển khai các dữ liệu dòng sử dụng các công cụ như Apache Kafka và Apache Spark.
-
Cloud: Các kỹ sư dữ liệu nên quen thuộc với các nền tảng tính toán Cloud, chẳng hạn như Amazon Web Services (AWS), Microsoft Azure và Google Cloud Platform (GCP), và có thể thiết kế và triển khai các giải pháp cơ sở hạ tầng dữ liệu trên các nền tảng này.
-
Quản lý, bảo mật và tuân thủ dữ liệu: Một phần rất quan trọng đó là quản lý, bảo mật, mã hóa dữ liệu, kiểm soát truy cập dữ liệu.
-
Giao tiếp: Và cuối cùng là kỹ năng giao tiếp tốt để có thể hợp tác với đồng nghiệp, giải thích các khái niệm kỹ thuật phức tạp cho các nhà quản lý không phải người làm kỹ thuật và trình bày công việc của mình trước đám đông.
Hi vọng bài viết này đã giúp bạn có cái nhìn tổng quan về vị trí này.