Dataset Streaming - Làm việc với 1.2 Terabytes dữ liệu mà không cần tải toàn bộ.
1) Giới thiệu về Streaming Dataset
Bộ dữ liệu OSCAR nặng 1.2 Terabytes, mình tin là rất ít người trong chúng ta có ổ cứng đủ để lưu và làm việc với bộ dữ liệu này. Vậy cách giải quyết như thế nào nhỉ?
Câu trả lời: Ta sẽ sử dụng/xây dựng một Streaming Dataset
Cơ chế tương tự Cursor trong MongoDB. Thay vì phải tải dòng một lúc thì khi bạn lặp Cursor đến vị trí dòng nào MongoDB mới tải dòng đó để ta xử lý.
Điều này cực kỳ hữu ích:
- Bạn không phải tải toàn bộ tập dữ liệu về máy
- Bạn muốn thử nghiệm vài samples nhanh
2) Trải nghiệm Streaming Dataset với HuggingFace
Cài đặt HuggingFace Dataset:
!pip install datasets
Sử dụng Dataset dưới dạng Streaming thay vì tải về toàn bộ:
Chú ý tham số streaming=True
from datasets import load_dataset dataset = load_dataset('oscar', "unshuffled_deduplicated_en", split='train', streaming=True) print(next(iter(dataset)))
Kết quả:
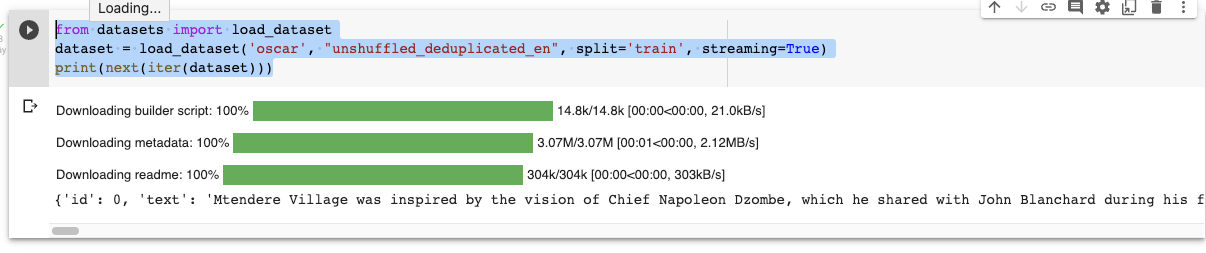
Biến dataaset thuộc lớp IterableDataset cho phép lặp tuần từ qua tất cả các phần tử.
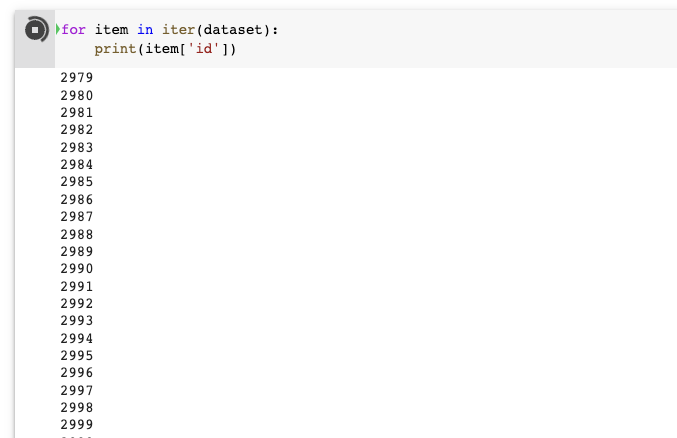
Bạn chỉ thực sự tải dữ liệu khi viết:
for item in iter(dataset): print(item['id'])
3) Lấy một phần của dữ liệu thế nào
Mình đã làm rất nhiều video về Tensorflow Dataset và cách thức lấy một phần data của HuggingFace Dataset cũng tương tự. Đó chính là hàm take
Bạn lấy 3 phần tử khỏi dataset và chuyển thành mảng.
dataset_head = dataset.take(3) list(dataset_head)
4) Xáo bộ dữ liệu thế nào?
Khi làm AI chắc chắn chúng ta cần phải quan tâm tới việc xáo dữ liệu đúng không? Vậy thì hàm shuffle sẽ giúp bạn làm điều này.
shuffled_dataset = dataset.shuffle(seed=42, buffer_size=1000)
Đây là tính năng tương tự ở bất kỳ một thư viện build dataset nào.
Chúng ta có đầy đủ công cụ hỗ trợ cho bạn tiền xử lý:
- Chia tập train/tập validation
- Hàm map
5) Nguồn tham khảo
- Treaming Dataset: https://huggingface.co/docs/datasets/stream