Ước lượng giá trị mất mát tối ưu dựa vào số lượng tham số
1) Khi bạn làm việc đủ lâu với một mô hình, bạn sẽ nắm được rất nhiều thông số quan trọng để tăng tốc trong những lần training tiếp theo
Có một điều rất thú vị mà có thể bạn quan tâm, khi bạn làm việc với một mô hình đủ lâu, bạn có thể hình thành mối tương quan giữa số lượng tham số của mô hình và giá trị mất mát tối ưu.
Trong năm qua, đội ngũ ProtonX đã train rất nhiều mô hình cho Studio. sử dụng GPT2 - Medium với 345 triệu tham số với rất nhiều domain khác nhau, từ tuyển dụng cho đến công thức nấu ăn rồi viết bài marketing, chuẩn SEO, vv.
Với những domain cụ thể, team có những con số tương đối chính xác để dự đoán được hiệu suất của mô hình. Ví dụ như sau:
- Với domain đơn giản như mô tả công việc (JD), chỉ cần khoảng 100.000 văn bản trở lên, bạn đã có thể tạo ra được một mô hình có khả năng sinh được ra miêu tả đủ dùng.
Đây là output cho vị trí phân tích dữ liệu:
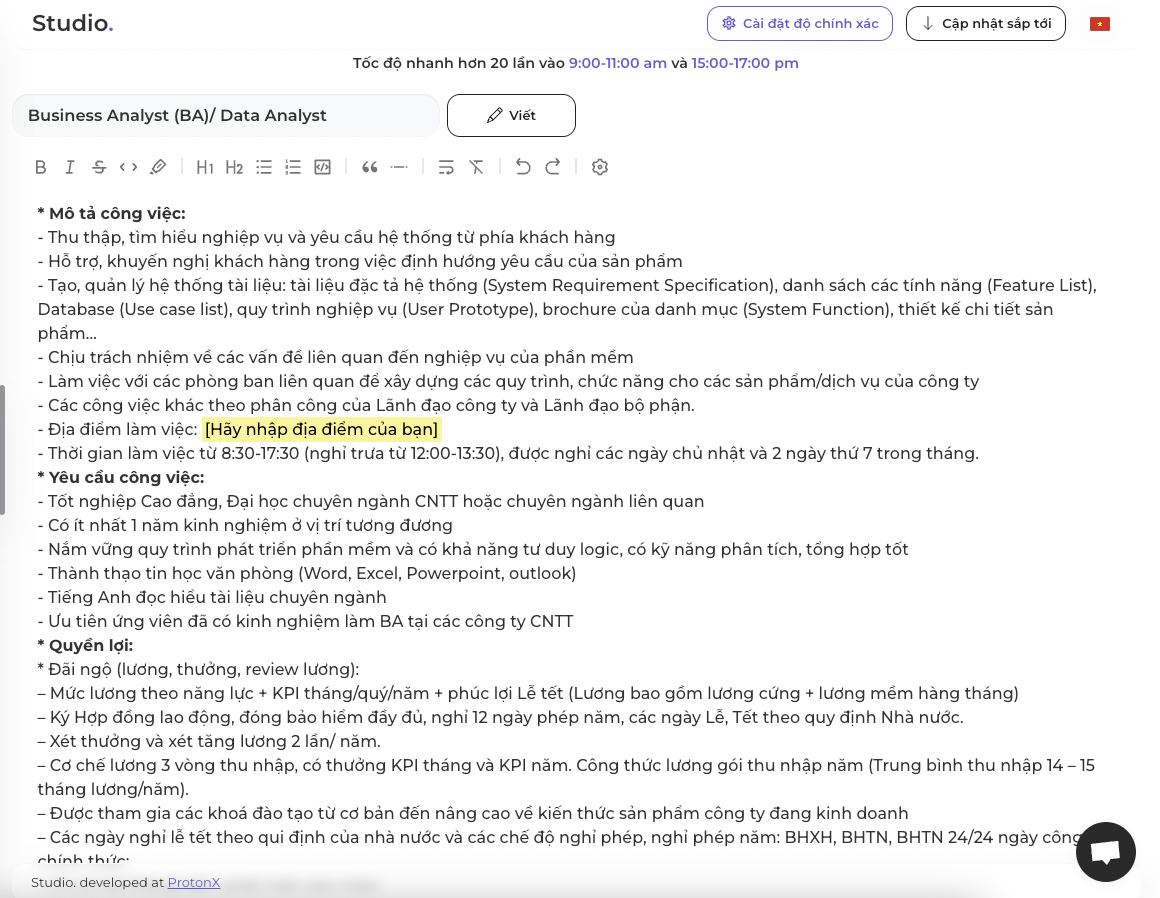
Theo người dùng phản hồi thì mô hình hiện tại đang hỗ trợ người dùng 50% trong việc viết miêu tả, tức là 50% còn lại người dùng cần chỉnh sửa và nhập các thông tin cá nhân như quyền lợi ứng viên, địa chỉ công ty.
2) Ước lượng giá trị mất mát tối ưu dựa vào số lượng tham số của mô hình
Gần đây team có đọc nghiên cứu Scaling Laws for Neural Language Models thì đã liên hệ trực tiếp quá trình training của team thì có một số nhận định khá tương đồng.
Có 3 luật quan trọng trong bài báo này nhưng trong bài viết này mình sẽ chỉ nhắc đến quy luật đầu tiên mà họ rút ra.
Với mô hình giới hạn tham số, giá trị mất mát tối ưu (hội tụ tốt) với lượng dataset đủ lớn sẽ xấp xỉ theo công thức sau:
Với và là hai giá trị cố định
- chính là giá trị mất mát tối ưu
- : số lượng tham số của mô hình
Áp dụng vào bài toán của team:
Hiện tại team có hơn 200.000 miêu tả công việc, nếu áp dụng công thức này thì giá trị mất mát hợp lý sẽ là:
Con số này khá thú vị, đó chính là con số mà team rất hay gặp trong khoảng training 7-10 epochs đầu tiên, vậy là nhận định này đã đúng với những gì thực tế diễn ra.
Ví dụ đây là epoch số 6 mà team đào tạo
'loss': 2.6251, 'learning_rate': 9.333333333333334e-06, 'epoch': 6.0}
30%|████████████████████████▉ | 37806/126020 [11:41:23<24:58:47, 1.02s/it]***** Running Evaluation *****
Num examples = 378055
Batch size = 8
{'eval_loss': 2.65189266204834, 'eval_runtime': 571.2631, 'eval_samples_per_second': 661.788, 'eval_steps_per_second': 20.682, 'epoch': 6.0}
30%|████████████████████████▉ | 37806/126020 [11:50:54<24:58:47, 1.02s/it]
Giá trị rất sát với công thức trên.
Tất nhiêu theo đánh giá của team, công thức này sẽ đúng hơn nữa khi dataset lớn hơn khoảng 1 triệu bản ghi, tuy nhiên là một trong những thước đo rất quan trọng giúp bạn có thể ước lượng được điểm dừng sớm.
Team rất mong bạn có thể tham khảo công thức này để tiết kiệm thời gian và có những insight quan trong mà mình làm việc mỗi ngày.