AI
Triton Inference Server
Tags
System DesignTriton Inference Server là gì?

Nguồn ảnh: tại đây
Mô hình Triton Inference Server là một framwork để triển khai các mô hình deep learning trên sản phẩm thực tế phát triển bởi NVIDIA. Triton cho phép triển khai dưới nhiều dạng kiến trúc khác nhau từ tập trung (centralized) cho đến multi-node. Ngoài ra nó còn cung cấp công cụ quản trị quá trình deployment của chúng ta.
Một số điểm đáng chú ý của Triton:
-
- Khả năng inference song song mạnh mẽ.
- Trường hợp 1: 2 request đến 2 model khác nhau

- Trường hợp 2: Nhiều request đến một mô hình, Triton sẽ giúp chúng ta đặt request vào hàng đợi để giảm tải cho GPU/CPU.
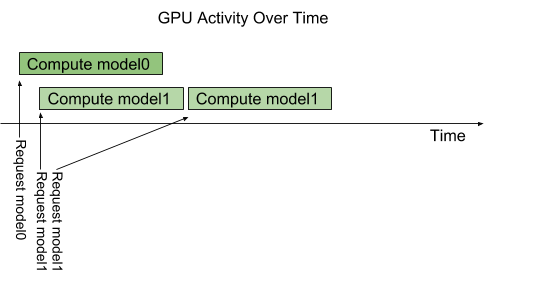
Triton hỗ trợ dynamic batching - tức là cho phép nhóm các request từ người dùng để thực hiện dự đoán theo batch. Lợi ích của việc này đó là cải thiện băng thông.
-
- Các định dạng mô hình thư viện hỗ trợ bao gồm TensorFlow, PyTorch, Caffe thậm chí là ONNX. Giao thức sử dụng để inference là Restful API, gRPC.
-
- Một trong những điểm mạnh lớn nhất của Triton là khả năng làm việc với nhiều mô hình với nhiều phiên bản khác nhau, cho phép deploy và quản lý dễ dàng trên môi trường production.
Team ProtonX đang đưa Triton vào sản phẩm của mình và trình bày tại lớp học Lớp học MLEs 02 - Xây dựng hệ thống học máy lớn. Bạn hãy đón xem nhé.