Dự đoán hạ tầng cần triển khai ChatGPT
Trong sự kiện Hướng dẫn đưa ChatGPT vào sản phẩm tuần trước có một câu hỏi rất hay đó là:
Thế để triển khai được mô hình ChatGPT thì phần cứng như thế nào ạ? Và triển khai như thế nào ạ?
Một câu hỏi rất hay, mặc dù OpenAI không hề công bố các kỹ thuật và hạ tầng này, dựa trên kinh nghiệm về triển khai mô hình GPT-2 trên Studio., team xin dự đoán một số kỹ thuật như sau?
1) Dự đoán kích cỡ mô hình của ChatGPT.
GPT-3 có 175 tỷ param, nếu mỗi param lưu trữ Float-16, quy ra kích cỡ
và theo chi tiết OpenAI công bố thì ChatGPT sử dụng GPT 3.5 khác GPT 3 ở chỗ OpenAI đưa học tăng cường với feedback của con người (RLHF) vào để finetune lại mô hình. Một số tin ngoài cho hay mô hình dao động trong khoảng 350GB đến 800GB.
Với kích cỡ như vậy, với một card đồ họa (GPU) thuộc loại thương mại mạnh mẽ nhất như bây giờ - A100 với 80GB RAM không thể chứa được mô hình này trong riêng một GPU.
2) Đưa mô hình để phục vụ người dùng
Trong trường hợp kích cỡ mô hình lớn hơn RAM của một GPU, nhưng không có nghĩa là chúng ta bó tay.
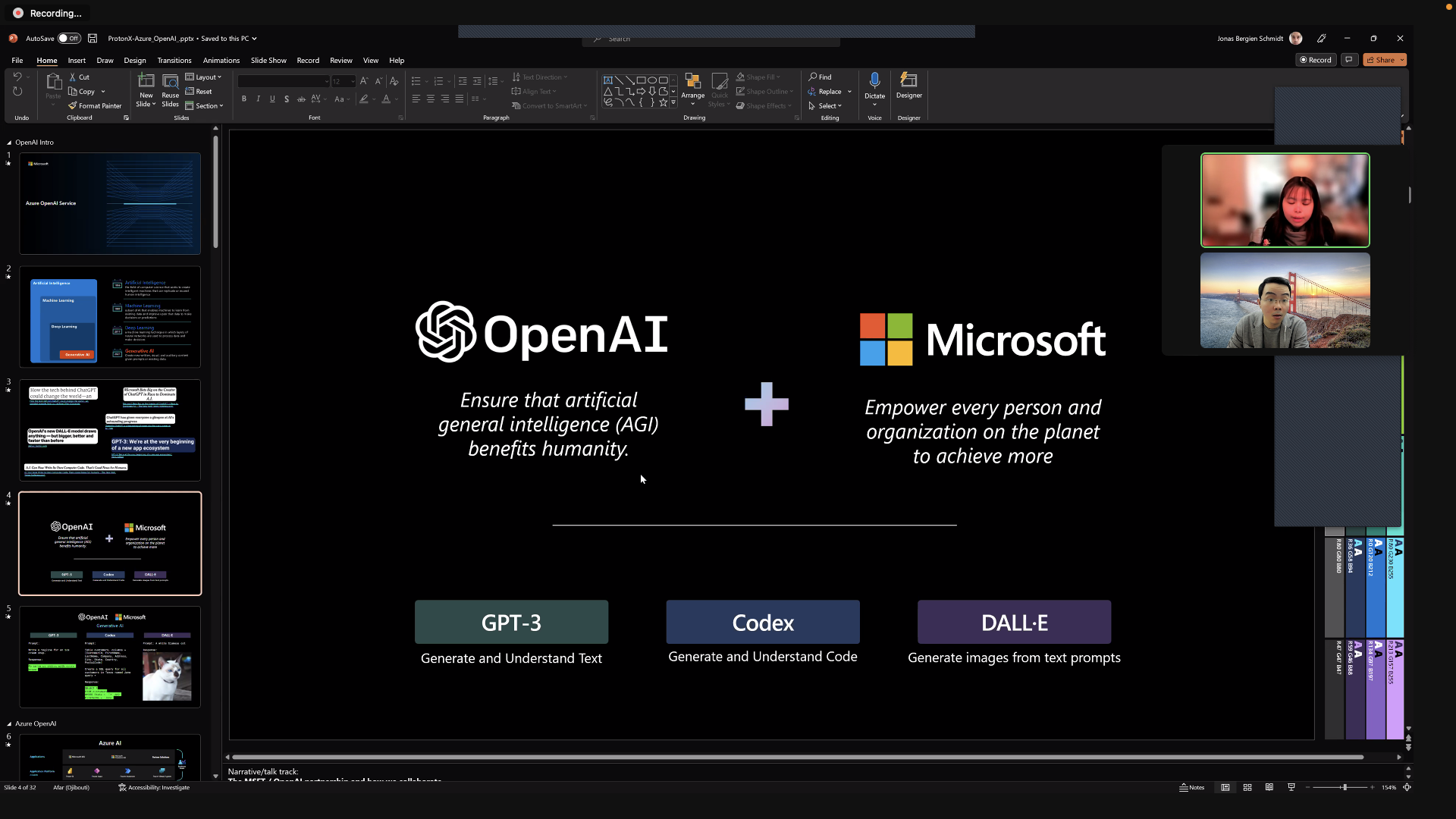
Giả sử chúng ta sẽ sử dụng 10 GPU A100 tương đương với không gian bộ nhớ là và với không gian này ta sẽ chứa đủ mô hình bên trên.
Sau đó ta sẽ chia mô hình thành 10 phần tương ứng cho 10 GPU mỗi GPU sẽ làm việc với một phần. Cơ chế này trong tiếng anh gọi là checkpoint shards.
Việc chia này không hề phức tạp với ChatGPT khi mô hình chỉ dùng gia tăng số lượng layer của Transformer Decoder
Việc tính toán sẽ tuần tự từ A100 đầu tiên cho đến A100 cuối. Tất nhiên nếu chỉ sử dụng 10 A100 một lúc thì với kích cỡ mô hình như vậy thì team dự đoán chỉ phục vụ được từ 5-15 người và còn cất rất nhiều kỹ thuật khác để tối ưu.
Một số thư viện AI đã hỗ trợ việc checkpoint shards ví dụ như HuggingFace
3) Scale hệ thống
Trước mắt để hiểu phần này bạn cần biết về Docker và cách đưa một mô hình AI vào trong Docker.
Bên trên chúng ta mới chỉ nhắc đến việc phục vụ được số lượng người dùng nhỏ, vậy với 100 triệu người dùng sau 2 tháng, chúng ta cần hệ thống như thế nào để có thể nhân rộng linh hoạt:
- Gia tăng GPUs khi người dùng tăng lên
- Giảm lượng GPUs khi người dùng ít dùng đi
Để scaling hiệu quả, thì team dự đoán có thể Kubernetes là một sự lựa chọn tốt.
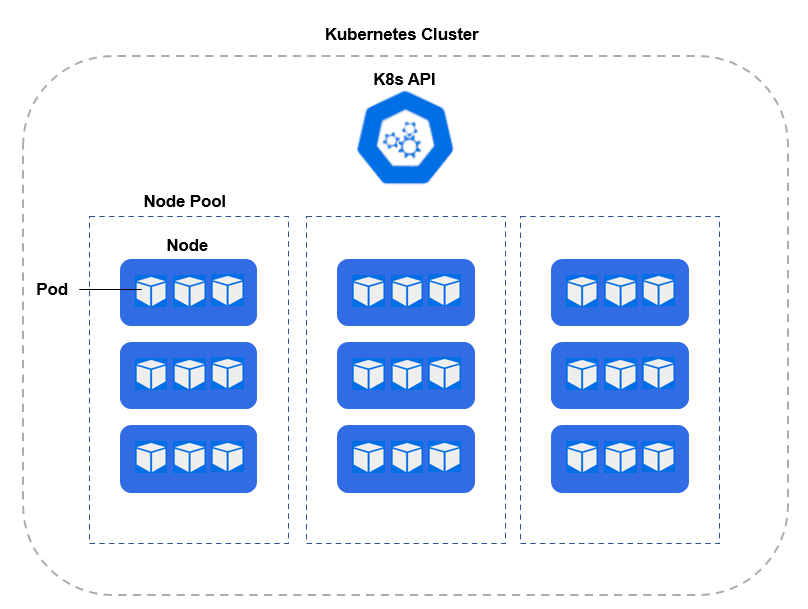
Ở đây Một Cluster sẽ có nhiều Node Pool, mỗi Node Pool sẽ có nhiều Node, ta có thể sử dụng mỗi node là một A100 và trong một pool có ít nhất là 10 Node.
Sau đó ta sẽ scale Node Pool trong cluster theo mong muốn trên.
Những đánh giá này hoàn toàn dựa trên kinh nghiệm của ProtonX team và không phải do OpenAI công bố tuy nhiên team hi vọng có thể cho bạn một số cái nhìn khả dụng về thiết kế hệ thống AI lớn như vậy.
Học được nhiều điều hay ho tương tự ở lớp học MLEs - Scale ML System 02.